Comment fait-on pour obtenir des courbes de charge en temps réel ?
Obtenir des courbes de charge, mais pourquoi faire ?
Collecter des données de manière automatique n’est jamais une mince affaire. Et pour ce qui est des données énergétiques, c’est d’autant plus compliqué qu’il existe un grand nombre de fournisseurs d’énergie qui ont tous leur propre fonctionnement. C’est la première raison qui fait que chez Deepki, nous avons toute une équipe dédiée à la collecte de données. Et la deuxième raison, c’est lui :

Ce petit boîtier à la couleur vive qui déchaîne les passions est le plus connu des compteurs communiquants notamment car il est destiné aux particuliers. De manière plus générale, nous avons assisté ces dernières années à l’arrivée en masse de compteurs communicants dans le secteur de l’énergie qui permettent de voir sa consommation en temps réel. Les entreprises qui veulent prendre en main leur consommation d’électricité ont donc à leur disposition toute une panoplie de compteurs qui, comme le linky, leur permettent de suivre leurs données de consommation.
Ces données de consommation, on les présente généralement sous la forme d’une courbe de charge.
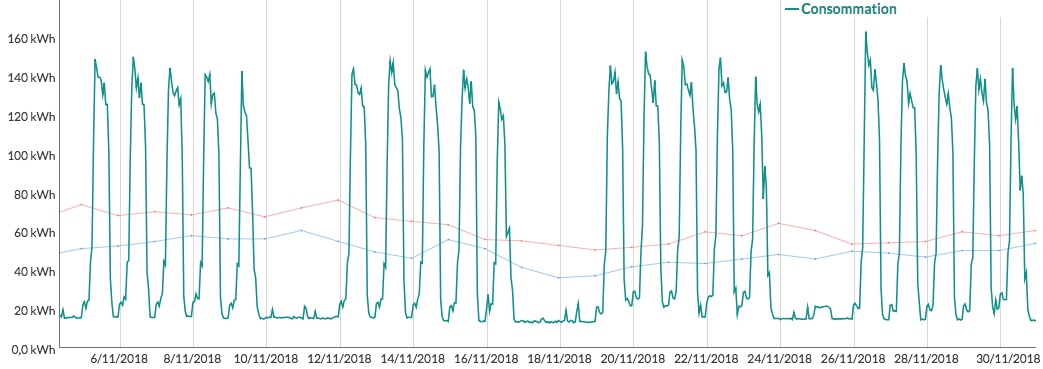
La courbe de charge, c’est vraiment le point de départ de l’analyse des données énergétiques. C’est en étudiant ces données que l’on va pouvoir détecter des anomalies de consommation. En d’autres termes, la courbe de charge, c’est le bloc de marbre dans lequel on va pouvoir tailler pour y faire ce que l’on veut.
Et dans cet article, nous verrons comment faire pour aller à la carrière de marbre, découper le bloc et le transporter jusqu’à l’atelier : comment collecter une courbe de charge.
Ok, j’ai compris en quoi les courbes de charge sont importantes. Mais pourquoi vouloir les récupérer en temps réel ?
Tout le monde ne le veut pas nécessairement. Mais certaines entreprises manipulent des appareils qui se détériorent en cas de sur-consommations. Et afin d’éviter la détérioration de tels appareils, avoir la consommation en temps réel est donc indispensable. On peut aussi évoquer les entreprises de mobilier urbain qui veulent détecter les branchements sauvages sur leurs appareils. Dans le cas d’un branchement sauvage, si on a l’information de la sur-consommation le lendemain, c’est souvent trop tard.
Seulement, comme la plupart des utilisateurs n’ont pas besoin de leurs données en temps réel, les compteurs communicants ne transmettent pas leurs données en permanence. Par exemple, pour un compteur de type linky (qui ne permet pas actuellement de récupérer des données en temps réel) qui fait 48 mesures par jour, la relève n’est par défaut effectuée qu’une seule fois par jour. Si on veut obtenir les données du jour, il va donc falloir demander au distributeur d’électricité de faire la relève du compteur.
En France, ça tombe bien, c’est Enedis qui distribue l’électricité sur 95% du territoire et il se trouve qu’ils ont développé une API qui permet de faire cette relève.
Comment fonctionne l’API d’Enedis ?
Dans cet article, nous n’allons pas évoquer la question (pourtant nécessaire) du consentement de l’utilisateur, nous allons uniquement nous concentrer sur la partie technique. Nous supposerons donc que l’on cherche à relever un compteur qui nous appartient.
- Pour obtenir les données du jour, on peut contacter l’API d’Enedis en lui communiquant via HTTP le numéro de notre compteur. L’API va alors répondre un identifiant qu’ils appellent le numéro d’affaire (qu’on utilisera plus tard).
- L’API contactera ensuite le compteur en question pour qu’il lui fournisse la relève actuelle. Ainsi, seuls les compteurs IP sont éligibles à ce service : ces compteurs sont actuellement reliés au réseau par la 3G ou la 4G. Les compteurs linky n’étant pas équipés de boîtier IP, ils ne sont donc pas éligibles à ce service et l’on va, dans la suite de cet article, uniquement évoquer les compteurs éligibles à ce service.
- Une fois la relève reçue, Enedis mettra à notre disposition le fichier de relève au format XML sur notre FTP. Ce fichier aura dans son nom le numéro d’affaire évoqué au 1er point.
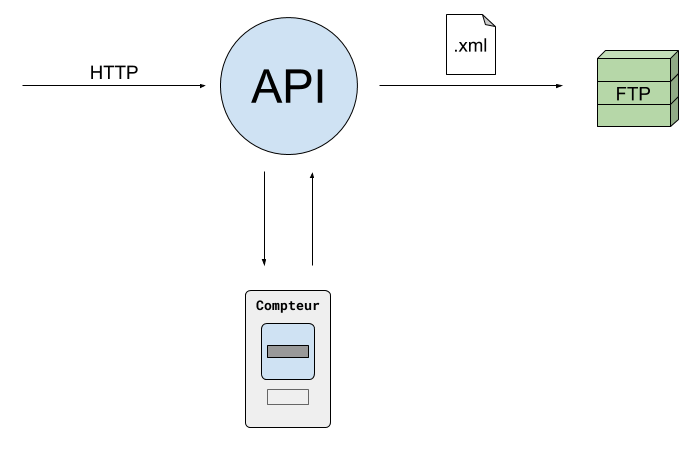
Dernier détail important à noter sur cette API : lorsque l’on demande un grand nombre de relèves en même temps, il peut y avoir un délai plus ou moins important (de l’ordre de plusieurs minutes voire de l’heure) entre l’appel à l’API et le dépôt du fichier sur le FTP. Ce délai est dû au fait que le compteur peut être occupé à faire autre chose au moment de l’appel ou bien qu’un problème réseau empêche le compteur de pouvoir communiquer correctement.
Comment est-ce qu’on peut industrialiser ce processus ?
Chez Deepki, pour traiter ce genre de tâches asynchrones, nous avons choisi une infrastructure qui s’appuie sur AWS (Amazon Web Services), le service de cloud computing d’Amazon.
Les lambdas
La première idée qu’on a eu, c’était d’utiliser le service de serverless d’AWS le plus simple à utiliser : les lambdas. Le principe, c’était de reproduire le schéma de structure suivant que l’on utilise régulièrement chez Deepki :

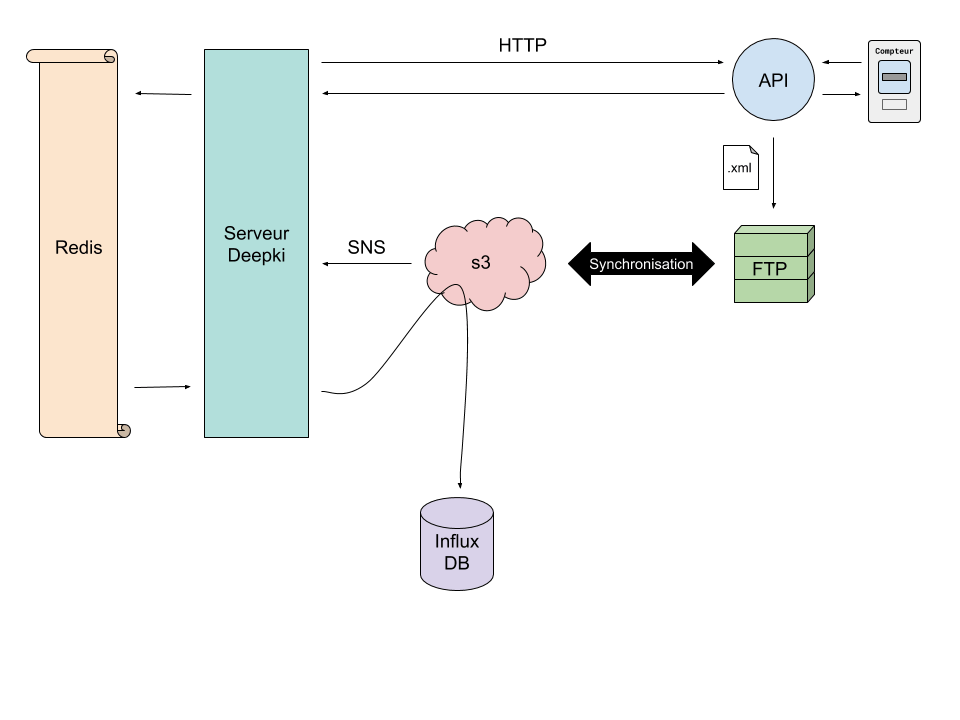
- Un script passe déjà toutes les dix minutes pour synchroniser notre FTP à s3 (Simple Storage Service, le service de stockage d’Amazon). Au vu du délai entre l’appel à l’API d’Enedis et le dépôt sur le FTP, c’est un temps tout à fait acceptable.
- Le dépôt du fichier sur s3 provoque le déclenchement de la lambda grâce au protocole SNS (Simple Notification Service).
- Enfin, la lambda va exécuter le code qui lit le fichier XML pour l’écrire dans la base de données.
Deux freins se sont posés quand on a pensé à cette solution :
- Comme les courbes de charge représentent un très grand nombre de données, nous ne les stockons pas dans une base de données classique mais dans une base de données dédiée. Nous avons fait le choix d’une base de donnée orientée Séries Temporelles, InfluxDB car parfaitement adaptée pour des courbes de charge. Or, jusqu’à présent, les lambdas que nous utilisions n’écrivaient pas sur la base InfluxDB et on n’avait pas nécessairement envie de développer cela en un premier temps.
- Les courbes de charge chez Deepki vivent dans deux environnements : un environnement de test et un environnement de production. Or, avec un tel système, nous n’avons pas trouvé de façon simple pour faire cohabiter ces deux environnements : quand on appelle l’API d’enedis, ils nous déposent le fichier sur notre FTP, mais nous n’avons pas moyen de savoir si c’est l’environnement de production qui a demandé ce fichier ou l’environnement de test. La lambda a bien accès au numéro d’affaire qui est dans le nom du fichier mais pas aux numéros d’affaire qui ont été demandés par l’environnement en question. La lambda n’aurait donc pas pu savoir quel fichier traiter sans avoir de séparation franche entre les deux environnements.
Nous avons alors écarté les lambdas.
La souscription à SNS
Dans la solution précédente, le dépôt du fichier engendrait un message SNS qui déclenchait la lambda. SNS est un protocole qui permet aux services d’AWS de communiquer entre eux, mais pas que ! Un message SNS peut également être transmis à une autre application. En adaptant un peu la solution précédente, nous avons donc envisagé la solution suivante :
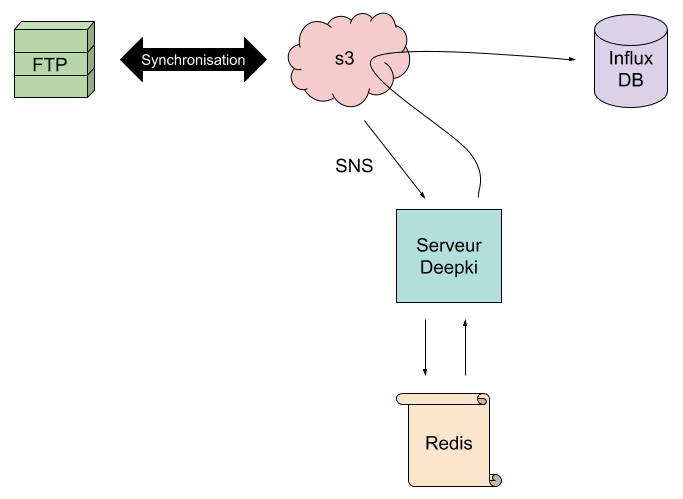
- Le script de synchronisation entre le FTP et s3 reste le même.
- Cette fois-ci, le dépôt sur s3 envoie un message SNS non pas pour déclencher une lambda mais pour appeler l’application de Deepki dédiée à la collecte.
- Cette application va consulter le numéro d’affaire que l’on aura au préalable stocké dans Redis, une base de données clef/valeurs très rapide.
- Si le numéro d’affaire correspond bien à une demande qui a été formulée par cet environnement, l’application va alors déléguer à une tache asynchrone l’action d’aller chercher le fichier complet sur s3 afin de le lire et de le traiter pour enfin l’insérer dans la base InfluxDB.
Et c’est cette solution que nous avons retenue !
Ce qui nous a séduit dans cette solution, c’est :
- Le délai pour faire toutes ces opérations et ainsi obtenir les courbes de charge du jour dans la base de données qui était parfaitement acceptable.
- Notre application principale qui passe d’un mode passif et inefficace à un mode événementiel et réactif.
- Les environnements de test et de production qui pouvaient cohabiter sans aucun problème.
Conclusion
Pour résumer, voilà deux schémas récapitulatifs de l’ensemble du parcours :

La solution que nous avons choisie pourrait être encore améliorée. Je pense notamment qu’on pourrait développer des lambdas qui écrivent sur la base InfluxDB et qui interrogeraient redis directement pour savoir si le numéro d’affaire est connu. Cela permettrait de ne plus du tout avoir à se servir du serveur (mise à part pour le déclenchement initial) mais c’est une solution un peu plus compliquée à mettre en place en particulier par rapport à nos contraintes de sécurité.
Pour finir, je me dois de vous dire toute la vérité. Cette solution nous a paru très séduisante quand nous l’avons conçue mais nous n’avions pas encore développé le module permettant de recevoir des messages SNS. C’est pour cela que j’aborderai lors de mon prochain article (qui sera, lui, plus technique) : comment s’abonner automatiquement à une souscription SNS.
Annexe
Vocabulaire :
- API : Interface de Programmation Applicative
- AWS : Amazon Web Services
- Lambda : L’un des services de serverless d’AWS
- s3 : Simple Storage Service
- Serverless : Infrastructure sans serveur dédié
- SNS : Simple Notification Service
- FTP : File Transfer Protocol
Cette entrée a été publiée dans deepki avec comme mot(s)-clef(s) enedis, serverless, aws, s3, sns, lambda, courbe de charge, temps réel
Les articles suivant pourraient également vous intéresser :
Vos commentaires
Super clair !
Bonjour, Je suis enseignant et dans le cadre scolaire, je dois réaliser un sujet autour de la consommation électrique. Auriez-vous la possibilité de m’une courbe de charge de consommation électrique d’un village français quelconque d’environ 50 habitants.
Bonjour Goudjili et merci pour votre commentaire ! Malheureusement, nous ne pouvons pas vous transmettre les données de nos clients car ce sont des données sensibles dont nous ne sommes pas propriétaires.
Pour avoir la courbe de charge de consommation électrique d’un village quelconque, il faudrait que chaque habitant de ce village (sans exception !) donne son accord (avec un mandat signé) à ce qu’un tiers puisse collecter ses données. Ensuite, ce tiers devra requêter chaque courbe de charge une par une puis les sommer pour obtenir la courbe globale de tout le village.
Bref, vous mettez le doigt sur un aspect important que j’ai préféré écarter pour cet article : qui a le droit de requêter ces données de consommation. Or, cette question est centrale dans notre métier et nous apportons un soin tout particulier à respecter les règles d’utilisation de l’API d’Enedis afin de ne collecter que les compteurs pour lesquels nous sommes mandatés.
Bon courage pour vos cours et à bientôt sur le blog technique de Deepki !
Bonjour, ceci a t-il evolué depuis 2020 ? améliorations , changements du fait de pbs de perfs ou autres ?
Bonjour Sylvain,
non cela n’a pas fondamentalement évolué en 3 ans, le design prenait dès le début en compte les questions de performances à venir.
Merci !
Merci pour votre réponse On prévoit justement nous aussi de mettre en place InfluxDB pour des courbes de charges aussi On se pose des questions sur l’exposition des données stockées dans InfluxDB , via juste l’api proposée par Influx , ou via une surcouche API WS “maison” qui elle utiliserait elle Influx ? Comment faites vous ?
Bonjour,
nous utilisons directement les API HTTP offertes par InfluxDB. Tous les appels sont authentifiés (avec rotation régulière des secrets) et un filtrage réseau pour ne pas exposer nos services sur Internet.
Bonne journée
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.