TypedDict vs DataClass en Python
Avez-vous déjà travaillé sur une très grande base de code, mélangeant choix historiques et nouvelles technologies ? C’est parfois difficile de comprendre toutes les intentions en parcourant un programme. A titre personnel, il m’est arrivé de me retrouver à lire des centaines de lignes de code python où étaient utilisées des classes, des dataclasses et des dictionaries un peu partout. Je n’étais pas capable de comprendre quels étaient les avantages à utiliser un TypedDict plutôt qu’une dataclass. Tout se ressemblait, et le code dans lequel je plongeais n’exprimait pas la différence.
Cela se produit régulièrement, si on ne fait pas attention à bien remanier son code lors de l’ajout d’une fonctionnalité ou lors d’une résolution de bugs, le code devient alors plus complexe et perd en lisibilité.
Dans cet article nous allons essayer de comprendre un peu mieux pourquoi utiliser un TypedDict ou une dataclass, quels sont leurs atouts et comment mieux concevoir notre code grâce au typage.
Tout d’abord, parlons des types
Chez Deepki, il y a deux ans, nous avons commencé à implémenter le typage pour nous aider à améliorer la compréhension et la qualité de notre code.
Le typage a été introduit dans Python via la PEP 484 :
Cette PEP vise à fournir une syntaxe standard pour le typage, ouvrant ainsi le code Python à l’analyse statique, à un remaniment du code plus simple, à une éventuelle vérification des types à l’exécution, et (dans certain cas) à la génération de code utilisant l’information de type.
Parmi ces objectifs, l’analyse statique est le plus important. Cela inclut le support des validateurs de types tels que mypy, ainsi que la fourniture d’une notation standard qui peut être utilisée par les IDEs pour la complétion et le remaniement de code.
Pour rappel, voici un exemple de définition de type d’une fonction :
# Sans typage
def find_user(name, age):
...
return User(**doc)
# Avec typage
def find_user(name: str, age: int) -> User:
...
return User(**doc)
Le typage permet aux développeurs de débusquer les bugs plus tôt, en utilisant des outils tels que mypy qui révèlent des anomalies lorsque les types ne sont pas respectés. Ces indications permettent de gagner beaucoup de temps plutôt que de découvrir les erreurs lors de l’exécution du programme.
Chez Deepki, nous avons même configuré nos éditeurs de code pour attraper ces erreurs et les afficher directement dans le code :

Ça nous fait gagner un temps fou !
À propos des classes et dataclasses
Le typage fonctionne très bien avec les classes.
Prenons un exemple :
from dataclasses import dataclass
@dataclass
class User:
name: str
city: str
@dataclass
class City:
name: str
is_polluted: bool
def serialize_user_city_pollution(user: User, city: City) -> str:
air_status = "polluted" if city.is_polluted else "clean"
return f"{user.Name} lives in {user.city} where the air is {air_status}" # <- 1st error
bob = User(name = "Bob", city = "Paris")
paris = City(id = "Paris", is_polluted = True) # <- 2nd error
print(serialize_user_city_pollution(bob, paris))
En précisant le type des entrées de la fonction, le code est plus compréhensible. On sait tout de suite avec quelles entités on travaille.
De plus, comme dit précédemment, il est possible d’exécuter mypy sur ce fichier ou de configurer son éditeur pour découvrir ces erreurs directement :
$ mypy file.py
area.py:10: error: "User" has no attribute "Name"; maybe "name"?
area.py:10: error: "City" has no attribute "id"
Found 2 errors in 1 file (checked 1 source file)
TypedDict
Quelle est la différence entre TypedDict et un dictionnaire ?
TypedDict est très similaire à un dictionnaire, avec une particularité supplémentaire : les clés sont définies à l’avance, ainsi que le type de chaque valeur. En réalité TypedDict est un protocol Python qui permet de typer les valeurs d’un dictionnaire (cf la PEP 544 : Protocols: Structural subtyping (static duck typing)).
Travailler avec TypedDict
Voici quelques avantages à utiliser TypedDict :
1. Cela permet de typer une variable avec un dictionnaire dont on connait les propriétés et leur type.
class User(TypedDict):
name: str
age: int
def is_old(user: User) -> bool:
return user["age"] > 70
C’est très utile quand on essaye de typer du code existant qui utilise des dictionnaires comme structure de données. Par exemple, lors d’un appel vers une API externe dont la réponse renvoyée est au format JSON, l’objet reçu peut être typé avec un TypedDict. Ainsi le contrat de l’API est respecté. Néanmoins il convient de valider les données, afin que le typage reste toujours vrai, même si l’API évolue.
Avoir ces structures de données typées vous aidera à avoir plus de contrôle sur votre code.
Une autre possibilité serait de remplacer ces modèles par des classes, cependant cela implique de remanier toutes les fonctions et classes qui les utilisent. Ce qui peut devenir très long, voire très compliqué, et parfois impossible.
C’est ce à quoi on est souvent confronté chez Deepki : des milliers de lignes de code héritées de plusieurs années de développement utilisant la plupart du temps des dictionnaires comme structure de données primaire. Ces données proviennent de plusieurs sources :
- Points d’accès à l’API de notre client web
- Fichiers CSV et Excel
- Fichiers YAML pour notre configuration
- Bibliothèques externes (ex: pandas)…
Nous sommes également confrontés à cela lorsque nous convertissons des dataframes en pur objet python. L’utilisation de TypedDict permet le typage de ces derniers afin de garantir après validation que l’on maitrise les données manipulées.
2. Cela traite les valeurs None comme optionnelles
class User(TypedDict):
name: str
age: int
email: str | None
User(name="Bob", age=32, email=None)
# Pas besoin de donner la valeur "None" pour l'email
print(User(name="Bob", age=32))
Ce programme affiche User(name="Bob", age=32).
En pratique, c’est très utile surtout pour les structures de données qui ne sont pas fixes.
TypedDict chez Deepki
Chez Deepki, nous utilisons TypedDict pour typer notre code un peu ancien sans devoir modifier des milliers de lignes. Ce qui est parfois notre seule option.
On peut également l’utiliser lorsque l’on souhaite manipuler des structures de données plus flexibles, comme c’est le cas avec la configuration par exemple. Avec de la configuration externe, on travaille généralement avec de nombreuses propriétés possédant des valeurs par défaut.
Ainsi on n’a pas besoin de les conserver dans notre entité courante et les valeurs None de la structure de données sont retirées.
Cela nous permet d’avoir plus de contrôle sur les données provenant de fichier YAML ou JSON en y ajoutant des types.
Pourquoi choisir une dataclass plutôt que TypedDict ?
Bien que ces deux structures de données se ressemblent, leur utilisation impose une approche de développement fondamentalement différente.
D’un coté les dataclasses imposent un cadre strict, cela nécessite donc de réfléchir à la structure des données en amont. A l’inverse, l’utilisation de TypedDict, de par son aspect beaucoup plus flexible, permet d’avancer et de se poser les questions au fil du développement, voire a postériori.
Nous allons voir néanmoins quelques avantages à utiliser les dataclasses.
Comparer les types des objets
Avec TypedDict il est difficile d’utiliser isinstance(), car isinstance compare la classe de l’objet, pas celle de ses attributs.
Or c’est possible avec les dataclasses.
Par exemple :
@dataclass
class User():
name: str
age: int
@dataclass
class ProjectUser():
name: str
age: int
def is_user(o: Union[User, ProjectUser]) -> bool:
return isinstance(o, User)
print(is_user(ProjectUser(name="Bob", age=32))) # False
print(is_user(User(name="Bob", age=32))) # True
Pouvoir comparer des objets entre eux peut se révéler très utile, par exemple pour valider des données en entrée.
Python 3.10 introduit Type Guards dans la PEP 647. Ce qui nous permet de spécifier le type d’une expression et donc de définir un type global pour un dictionnaire.
Par exemple :
class User(TypedDict):
name: str
age: int
class ProjectUser(TypedDict):
name: str
age: int
def is_user(o: dict) -> "TypeGuard[User]":
try:
return isinstance(o["name"], str) and isinstance(o["age"], int)
except KeyError:
return False
print(is_user(User(name="Bob", age=32))) # True
print(is_user(ProjectUser(name="Bob", age=32))) # True
Cependant, comme le montre cet exemple, le type d’un dictionnaire dépend du type de ses attributs, et il n’est donc pas possible de différencier un User d’un ProjectUser, comme c’était le cas avec l’utilisation des dataclasses.
De plus, lors de l’instanciation d’un TypedDict ou d’une dataclasse, il ne faut pas oublier que les vérifications de types ne se font pas lors de l’exécution du code. Ainsi il est possible d’instancier un objet avec des attributs qui ne respectent pas le typage :
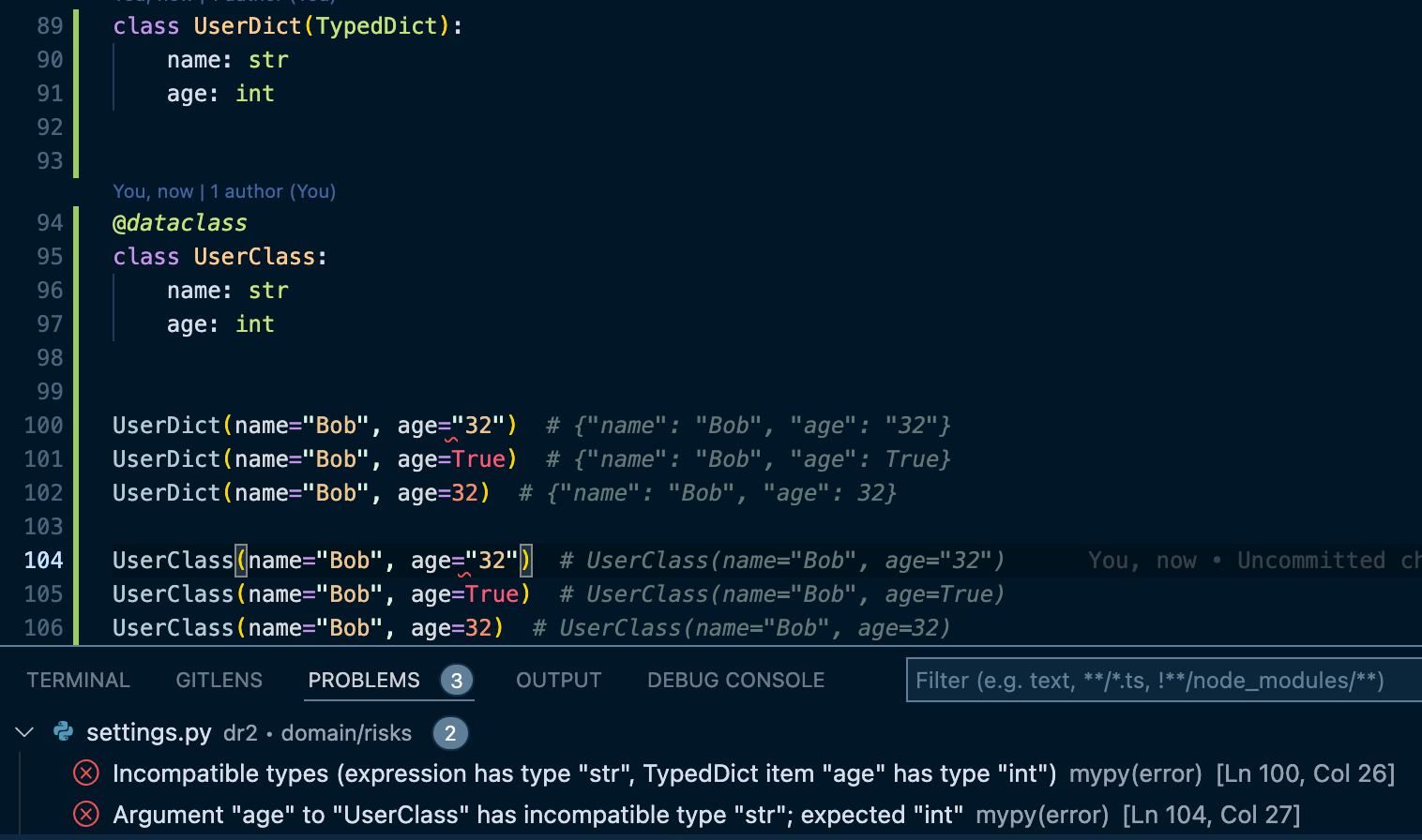
Le code s’exécute sans soucis, malgré les problèmes détectés par mypy.
La comparaison sélective
Avec les dataclasses, il est possible de selectionner les attributs que l’on souhaite comparer. Pour cela il suffit de redéfinir la méthode magique __eq__, par exemple :
@dataclass
class User():
email: str
name: str
age: int
def __eq__(self, other):
if not isinstance(other, User):
return NotImplemented
return self.name == other.name and self.email == other.email
user1 = User(email="bob.dylan@deepki.com", name="Bob", age=32)
user2 = User(email="bob.dylan@deepki.com", name="Bob", age=30)
print(user1 == user2) # True
En effet l’âge d’un User change chaque année et ne doit pas faire partie de la comparaison.
Tandis qu’avec les TypedDicts, la comparaison s’effectue sur tous les attributs.
L’utilisation des attributs virtuels
Un autre avantage à utiliser des dataclasses par rapport aux TypedDicts est la possibilité de définir des attributs virtuels (aussi appelés propriétés) :
@dataclass
class Foo:
value: float
@property
def rounded_value(self):
return int(value)
Cette pratique ouvre le champ des possibles et permet d’approcher un peu plus la programmation orientée objet, ainsi que tous les avantages qu’elle offre.
Conclusion
En réalité les dataclasses ne remplacent pas vraiment TypedDict, mais les deux sont complémentaires.
TypedDict est généralement une bonne solution lorsque la source des données provient de l’extérieur (JSON, YAML, …) et peut varier de structure. Il permet également de typer des dictionnaires déjà existants sans avoir à modifier tout son code pour passer par d’autres types de structures de données comme les dataclasses par exemple.
Cependant, lorsque c’est possible, utiliser les dataclasses présente ces avantages :
- Elles permettent une déclaration explicite des attributs d’un objet tout en intégrant le typage
- Cela donne des indices sur les types des attributs grâce aux type hints
- Les erreurs lors de la tentative d’accès à des attributs qui n’existent pas sont plus intuitives
- Les dataclasses peuvent être immutables (en utilisant l’argument frozen)
- Et enfin, les dataclasses viennent avec un meilleur support pour les IDE (par exemple, renommage, complétion de code…)
Voici un tableau comparatif des principales différences entre ces deux structures de données :
| Dataclass | TypedDict | |
|---|---|---|
| Utilisation du typage | ✅ | ✅ |
| Flexibilité sur la structure de donnée | ❌ | ✅ |
| Approche de développement | en amont | à postériori |
| Comparaison entre objets | ✅ | ❌ |
| Erreurs +compréhensibles & support IDE | ✅ | ❌ |
| Programmation Orientée Object | ✅ | ❌ |
A titre personnel, je préfère nettement utiliser des dataclasses quand c’est possible, qui rendent le code beaucoup plus clair et lisible, en manipulant des objets qui ont un sens réel dans l’application.
Chez Deepki, cette pratique ne fait que s’amplifier, et nous permet aujourd’hui d’améliorer la qualité de notre application et l’interopérabilité entre chaque développeur à travailler sur une très grande base de code.
Sources
- TypedDict vs dataclasses in Python
- PEP 484 – Type Hints
- Welcome to mypy documentation!
- Reddit article : Would you prefer a data class instance (no methods, just attributes), over a typed dict, or a named tuple?
- DataClass vs NamedTuple vs Object: A Battle of Performance in Python
- Data Classes: doc python
- PEP 647 – Type Guards
Cette entrée a été publiée dans programmation avec comme mot(s)-clef(s) python
Les articles suivant pourraient également vous intéresser :
- La bonne et la mauvaise review par Sébastien Bizet
- Dark mode vs Light mode : accessibilité et éco-conception par Jean-Baptiste Bergy
- Principes SOLID et comment les appliquer en Python par Mariana ROLDAN VELEZ
- Pydantic, la révolution de python ? par Pablo Abril
- Comment utiliser les fixtures pytest en autouse tout en maîtrisant ses effets de bord ? par Amaury Boin
Vos commentaires
Intéressant, est-ce qu’il vous arrive de valider un dict avec un TypedDict donné ? Si oui, comment faites-vous ?
Bonjour François,
Ce n’est pas quelque chose que l’on pratique beaucoup chez Deepki. On utilise généralement TypedDict en surcouche de code existant pour faciliter la mise en place du typing.
Néanmoins, il y a bien un endroit où on valide nos dicts avec TypedDict. Au niveau de l’entrée/sortie de nos événements (ESB), lors de leur sérialisation/déserialisation.
Dans ce cas là, on peut voir le TypedDict comme une référence (un mapping key-type). Il suffit alors de s’assurer que :
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.