Comment utiliser les Lambda Layers et optimiser son code serverless ?
Historiquement, les applications web étaient entièrement gérées par les serveurs, ces derniers sont responsables de répartir les ressources IT pour chaque entité de l’architecture. Mais imaginons le cas des grandes entreprises avec des infrastructures robustes.
Petit à petit, on commence à installer des nouveaux serveurs, et faire grossir toute l’infrastructure, par conséquent, les déploiements deviennent plus compliqués et difficilement gérés.
On commence à agrandir toute l’infrastructure alors que seulement un ou deux services ont vraiment besoin de ressources supplémentaires, tout cela finit par peser sur les finances des entreprises, mais aussi sur la motivation des développeurs qui ne se concentrent plus sur l’innovation, mais plutôt sur la maintenance et la stabilité opérationnelle.
Avec l’arrivée des plateformes de cloud comme AWS, Google Cloud ou Azure, de nouveaux services ont été mis en place pour aider les entreprises à monter en échelle rapidement en cassant les monolithes en petits morceaux avec ce qu’on appelle le Serverless.
C’est quoi déjà Serverless ?
Serverless ou serverless computing, est un ensemble de services fournis par les plateformes de cloud qui permet d’exécuter un morceau de code en allouant d’une manière dynamique les ressources nécessaires (mémoire, cpu …). Ainsi on ne paie que les ressources utilisées pendant l’exécution du code.
Le code s’exécute dans ce qu’on appelle des conteneurs stateless (sans état), le stockage est crée et éliminé avec le conteneur. Le but du serverless est de transformer les données, et non pas les stocker, les données traitées doivent être stockées dans un service backend séparé.
Les conteneurs sont gérés par des fournisseurs comme AWS qui s’occupent de la gestion des ressources nécessaires, Ce qui reste à faire coté développeur est d’importer le code sous forme d’une fonction, on parle alors de fonctions en tant que services ou FaaS.
Dans cet article, on va s’intéresser à un seul service d’AWS pour sa simplicité de mise en place, il s’agit de AWS Lambda. Regardons comment cela fonctionne.
AWS Lambda
Les fonctions Lambda peuvent réagir à un grand nombre d’évènements, comme par exemple la création ou la suppression d’un fichier sur S3, une requête HTTP (sur un « Endpoint »), ou encore un changement dans la base de données.
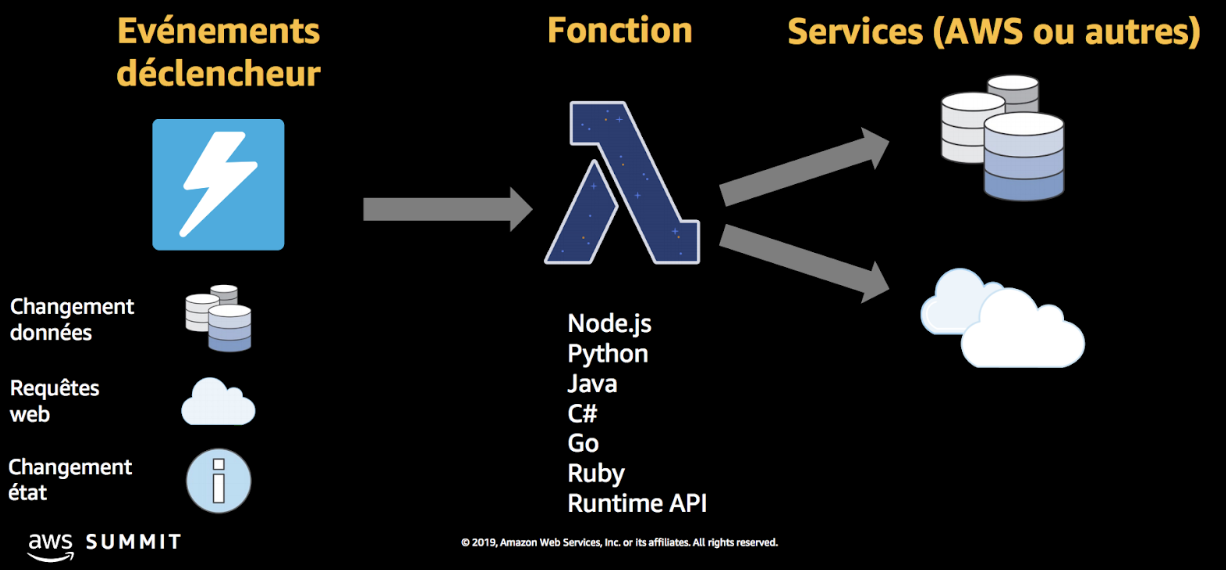
Lambda supporte plusieurs environnements, dans notre exemple, ce sera python 3.6.
Les autres avantages de Lambda sont nombreux, et il nous faudrait un deuxième article pour tout détailler, mais on va se limiter seulement sur quelques unes comme la possibilité de partage du code avec AWS Lambda Layers.
Les couches Lambda (ou Lambda Layers)
Lambda Layers est une nouveauté publiée par AWS en novembre 2018 et qui représente une amélioration majeure. Lambda Layers permet de promouvoir le partage et la réutilisation du code sur plusieurs fonctions Lambda, cela consiste à déployer une Layer et la référencer dans plusieurs fonctions, une Layer peut être un fichier python, ou même un package connu comme pandas.
Ce qu’on va voir
Cet article est composé de deux parties, dans la première je vais expliquer les étapes à suivre pour créer une simple Lambda Layer qu’on va utiliser dans une fonction Lambda, et dans la deuxième partie on va tirer profit de la même démarche pour utiliser le package python pandas en tant que Lambda Layer. Cela est très utile quand vous avez un grand nombre de Lambdas qui utilisent le même package.
Et pour finir je vais vous montrer comment utiliser le framework Serverless pour déployer à partir d’un simple fichier de configuration et quelques lignes de commande ces Lambda Layers.
Avant de commencer
A titre d’information, quand une couche zippée est chargée, elle est dé-zippée dans le dossier /opt. Pour que votre
fonction lambda puisse importer les bibliothèques contenues dans la couche, celle-ci doit être placée dans le
sous-répertoire python du dossier /opt. Par exemple pour python 2.7, le chemin complet est /opt/python. Pour python
3.6, ce chemin est /opt/python/lib/python3.6/site-packages. Je vous renvoie vers
la documentation chez AWS pour creuser
un peu plus le sujet.
On commence
Créez une simple fonction sample_func.py
def hello():
print("Hello Deepkies")
Et mettez ce fichier dans un dossier appelé python, puis zippez le.
zip -r layer_sample.zip ./python
Pour uploader le fichier layer_sample.zip en tant que Lambda Layer, il suffit de se connecter à la console AWS Lambda,
et de cliquer sur Create layer.

Ensuite, il faut configurer votre Lambda Layer et puis charger le zip.
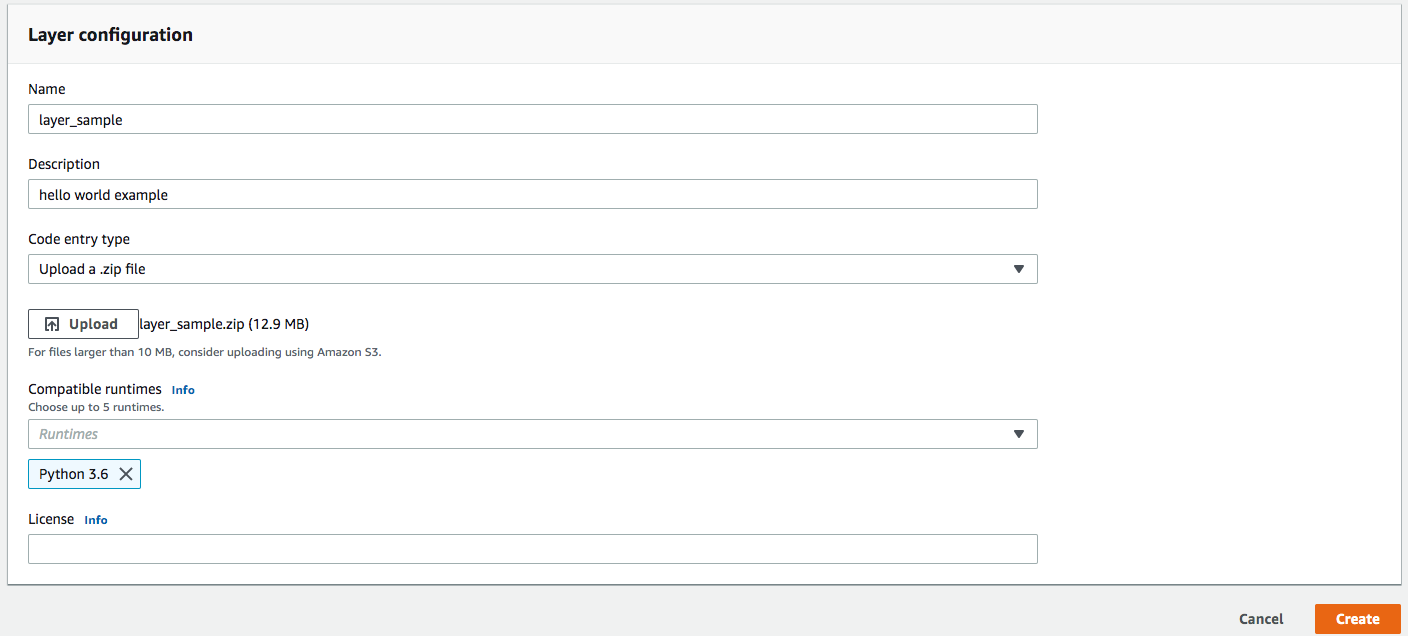
Cliquez sur Create.
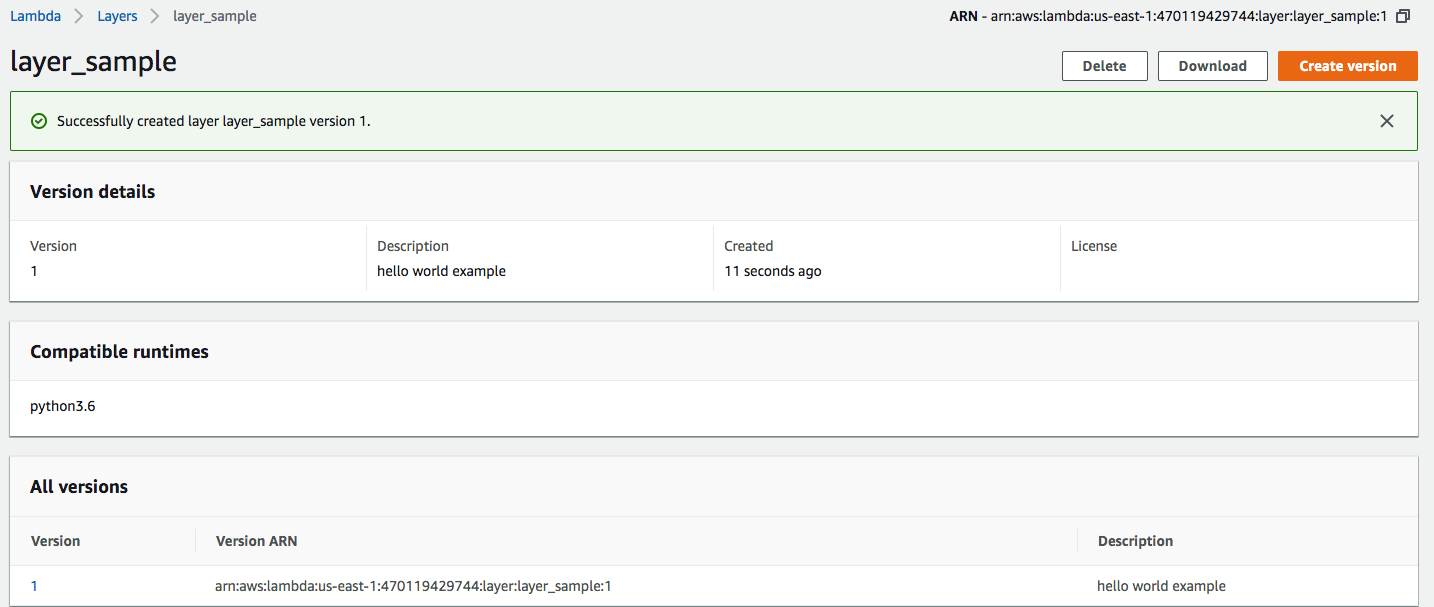
Félicitations, vous venez de créer votre première Lambda Layer !
Testons maintenant cette Lambda Layer depuis une fonction Lambda. Toujours dans la console AWS
Lambda, créez une nouvelle fonction Lambda avec le même environnement, puis cliquez sur Add layer.
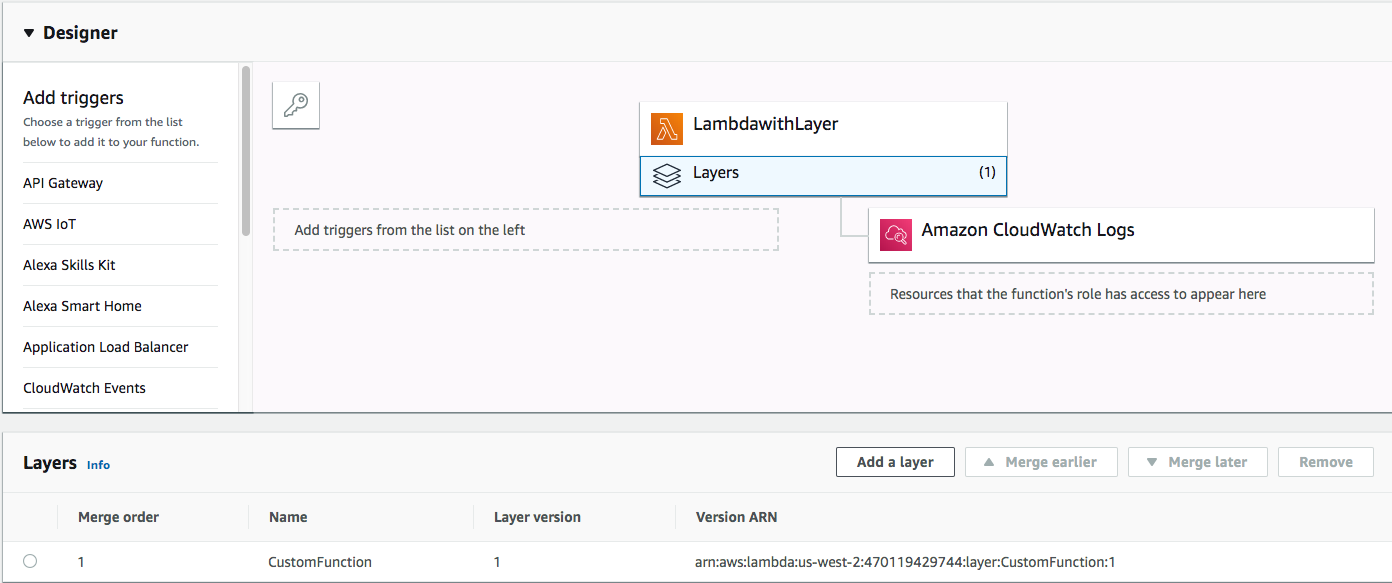
Comme vous pouvez le constater, la console vous suggère déjà les Lambda Layers qui sont compatibles avec votre fonction Lambda, vous pouvez aussi choisir la version de votre Lambda Layer dans le cas où celle-ci a déjà été créée.
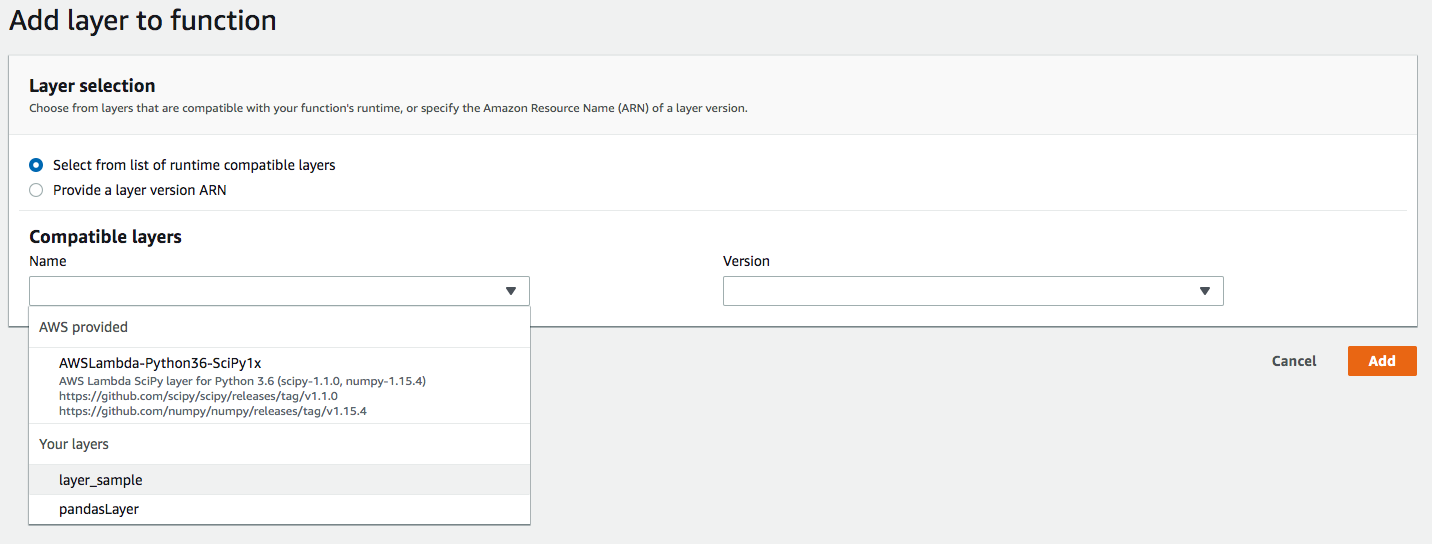
Cliquez sur Add : vous venez de créer une fonction Lambda avec une Layer. Par ailleurs, il n’y a pas beaucoup de
choses à ajouter dans le code sauf un simple import :
import sample_func as func
def lambda_handler(event, context):
func.hello()
return {
'statusCode': 200,
'body': 'bla bla!'
}
Créer une Lambda Layer avec la librairie pandas
Dans cette partie, on va voir une autre utilisation des Lambda Layers qui permet d’utiliser des packages python tel que pandas en tant que layer.
Pour commencer, créez un fichier requirements.txt :
pandas==0.23.4
Si vous avez d’autres packages, il suffit de mettre à jour le fichier requirements.txt.
On va ensuite utiliser ce script pour installer pandas dans une image Docker compatible avec AWS Lambda. Cette étape est nécessaire, parce que une fonction Lambda utilise le système d’exploitation Amazon linux, et il faut donc avoir un package pandas binairement compatible avec ce système (Je vous invite à lire la documentation de docker-lambda pour aller plus loin).
export PKG_DIR="python"
rm -rf ${PKG_DIR} && mkdir -p ${PKG_DIR}
docker run --rm -v $(pwd):/foo -w /foo lambci/lambda:build-python3.6 \
pip install -r requirements.txt -t ${PKG_DIR}
Il ne reste qu’à générer le fichier zip qui sera uploadé en tant que Lambda Layer.
chmod +x create_packages.sh
./create_packages.sh
zip -r Python36-Pandas23.zip .
Et voila, c’est tout ^_^ le reste est simple, il suffit d’aller à la console pour l’uploader et tester comme on l’a fait dans l’exemple précèdent.
import numpy as np
import pandas as pd
def handler(event, context):
df = pd.DataFrame(np.random.randint(0,6,size=(6, 4)), columns=list('ABCD'))
print(df)
Intégrer les Layers dans les fonctions Lambda avec le framework Serverless
Serverless est un framework orienté évènement (event-driven) comme AWS Lambda ou Google Cloud Functions. C’est un outil en ligne de commande permettant ainsi d’automatiser les workflows et de déployer facilement les architectures serverless.
Pour mettre en place votre environnement, exécutez ce script :
# Installing the serverless cli
npm install -g serverless
# Configure AWS profile (with Serverless CLI)
serverless config credentials --provider <profile_name> --key <access_key_id> \
--secret <secret_access_key>
# Create a new working folder and set up subfolders
mkdir serverless-with-layer
cd serverless-with-layer
mkdir -p layers/pandas
Configuration
Créez un fichier serverless.yml avec le paramétrage ci-dessous et copiez les fichiers create_packages.sh,
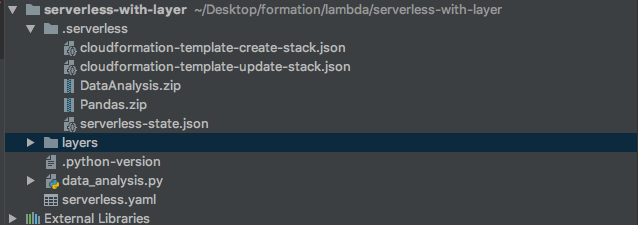
data_analysis.py et requirements.txt, avec l’arborescence suivante:
serverless-with-layer
|__ data_analysis.py
|__ serverless.yaml
|__ layers
|__ pandas
|__ create_packages.sh
|__ requirements.txt
serverless.yml
service: sample-service # Name of the service, which is used as a prefix to all function names.
frameworkVersion: ">=1.34.0" # Layers are supported from version 1.34
provider:
name: aws # Assuming this is for AWS Lambda.
stage: dev # typically either dev/staging/prod (or production), this is also added to all function names.
profile: hamza-deepki # Name of the pre-configured AWS profile that is founnd in ~/.aws/confidentials.
region: us-east-1 # Name of the region to deploy all functions to.
runtime: python3.6 # AWS Lambda runtime
# AWS Lambda Layers
layers:
Pandas:
path: layers/pandas # required, path to layer contents on disk
name: ${self:service}-Python36-Pandas23x # optional, Deployed Lambda layer name
description: Pandas 0.23.x with Python 3.6 # optional, Description to publish to AWS
compatibleRuntimes: # optional, a list of runtimes this layer is compatible with
- python3.6
licenseInfo: MIT License # optional, a string specifying license information.
allowedAccounts: # optional, a list of AWS account IDs allowed to access this layer.
- "*"
package:
individually: true
# AWS Lambda Functions
functions:
DataAnalysis:
handler: data_analysis.handler
layers:
- { Ref: PandasLambdaLayer }
# Note the reference name is always the CamelCase version of the layer name with LambdaLayer suffix.
# Custom configuration of all resources including Lambda Function, IAM Role, S3 Bucket, ...
resources:
Resources:
DataAnalysisLambdaFunction: # name is always the CamelCase version of the layer with LambdaLayer suffix.
Type: AWS::Lambda::Function
Properties:
MemorySize: 128
Timeout: 5
Pour plus d’informations sur ce paramétrage, c’est ici.
Packagez ensuite votre fonction lambda avec la layer :
pushd layers/pandas && chmod +x create_packages.sh && ./create_packages.sh && popd
serverless package
Comme vous l’avez peut-être remarqué, il n’est plus nécessaire de zipper à la main notre livrable, c’est le framework qui se charge de zipper la fonction Lambda ainsi que les Lambda Layers.
Déploiement
Pour déployer, exécutez la commande suivante :
serverless deploy --package .serverless
Et c’est fini , vous n’avez plus qu’aller à votre console AWS pour tester.
Conclusion
Attention à ne pas surcharger vos fonctions Lambda : vous ne pouvez avoir que cinq Lambda Layers par fonction, et la taille de votre package de déploiement est limitée. Si certaines couches sont très volumineuses et que le package de déploiement Lambda dépasse 250 Mo, le déploiement échouera.
Lambda Layers est un service très puissant pour gérer et partager vos dépendances sur vos différentes fonctions Lambda, et ainsi mieux contrôler les mises à jour et la gestion des versions.
Cette entrée a été publiée dans architecture avec comme mot(s)-clef(s) serverless, lambda, aws, layers
Les articles suivant pourraient également vous intéresser :
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.