Pydantic, la révolution de python ?
J’ai eu l’opportunité, en février 2023, d’assister à une conférence de Samuel Colvin au FOSDEM à Bruxelles dans le cadre de mes fonctions chez Deepki. Il présentait une librairie de sa création : Pydantic. Je vais, à travers cet article de blog, vous présenter cette librairie, pourquoi je pense qu’elle révolutionne le langage Python et l’utilisation que l’on en fait chez Deepki.
Alors, c’est quoi Pydantic ?
Une image vaut bien mille mots il paraît, de la même façon qu’une slide de l’auteur fait encore mieux l’affaire. Pydantic est tout simplement une librairie de validation de données. Cette librairie permet donc de créér des modèles de données et de tout simplement s’assurer de leur conformité.
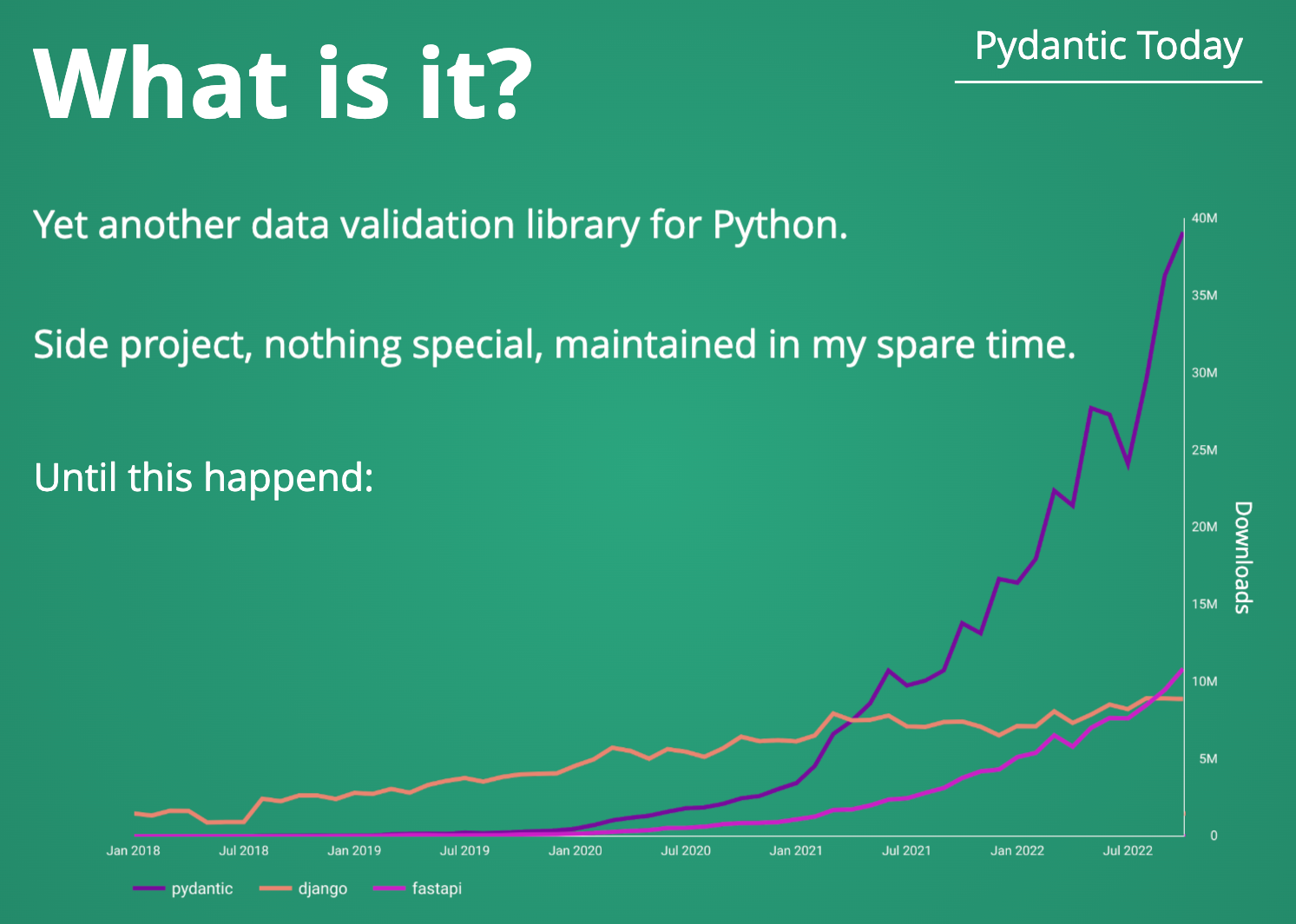
Nous l’utilisons désormais dans mon équipe et je trouve maintenant complètement impensable de s’en séparer.
A quelle problématique cette librairie répond-elle ?
Voici un exemple très concret et courant d’utilisation d’une dataclasse pour définir une structure de données. L’intention est très bonne, le développeur a accès à un type bien défini et se sent en confiance lorsqu’il va l’utiliser.
@dataclass
class User:
id: str
name: Optional[str]
email: Optional[str]
Or, voici qu’un développeur décide d’utiliser cette classe pour implémenter une nouvelle fonctionnalité. Il se trouve qu’il fait quelques erreurs lors de son développement, qui aboutissent à un code complètement bogué. Ce cas représente très bien un des inconvénients d’un langage dont le typage est dynamique : une variable ne se voit pas assigner un type, seulement sa valeur en possède. Python ne remonte aucun avertissement sur ce genre d’utilisation nativement.
user = User(id=42, name="Pablo", email=42)
print(user.email)
#> 42
Il est possible de partiellement répondre à cette problématique en utilisant un outil d’analyse statique (permet de détecter les erreurs avant le lancement du code) comme mypy. L’outil ne répond cependant pas totalement à notre problématique car il est intimement lié à la quantité et précision de typage fait par les développeurs. Par exemple utiliser le type Iterator est valide pour les types list, tuple, sets ou encore dict, ceci peut laisser passer des erreurs si ce n’est pas voulu.
Comment on utilise-t-on Pydantic ?
Commençons par créer notre premier modèle et voyons comment l’utiliser. Si vous êtes amateur de python, vous remarquerez très vite la ressemblance avec la syntaxe d’une dataclasse (Je vous conseille par ailleurs l’excellent article de Pierre Assemat sur les dataclasses)
Définissons un modèle de données
Notre point de départ, définir un modèle de données représentant une entité métier.
Voici un exemple définissant un utilisateur, observez la facilité de lecture qu’offre Pydantic, même un néophyte est capable de comprendre de quoi il retourne. En effet Pydantic ne s’appuie que sur des concepts déjà connus des développeurs : le typage et les classes. Nous n’avons pas de mise à niveau à faire pour faire nos opérations basiques.
from typing import Annotated
from datetime import datetime
from pydantic import BaseModel, PositiveInt, EmailStr, PastDate, HttpUrl, UUID4, field_validator
class User(BaseModel):
id: UUID4
name: str
email: EmailStr
birth_date: PastDate
websites: list[HttpUrl] | None
signup: datetime | None
Notez d’ailleurs l’utilisation de types qui n’existent actuellement pas dans Python. Pydantic nous fournit toute une ribambelle de types communément utilisés qui sont utilisables directement, permettant de garder la base de code toujours aussi lisible (ça ressemble à de l’anglais).
Ajoutons des règles de validation sur mesure
Parfois, les types de Python ou Pydantic ne suffisent pas à faire respecter des contraintes métier sur nos données. On peut alors créér des validateurs sur mesure. Nous définissons donc ici un validateur pour le nom de l’utilisateur : nous souhaitons qu’il appartienne à une liste prédéfinie et le formatter (décorateur @field_validator).
class User(BaseModel):
id: UUID4
name: str
email: EmailStr
birth_date: PastDate
websites: list[HttpUrl] | None
signup: datetime | None
@field_validator("name")
def name_is_allowed(cls, value: str) -> str:
if value not in ["Clement", "Paul", "Julie", "Alix", "Jar Jar Binks"]:
raise ValueError("This name is not allowed")
return value.lowercase().capitalize()
Créons un champ calculé dynamiquement
Il peut arriver que nous souhaitions avoir des données calculées à partir d’autres données dans notre modèle, cela peut être aisément implémenté grâce aux computed_fields. Nous définissons ici une propriété dynamique qui nous renvoie l’âge actuel de notre utilisateur, calculé grâce à sa date de naissance renseignée dans le modèle de base.
class User(BaseModel):
id: UUID4
name: str
email: EmailStr
birth_date: PastDate
websites: list[HttpUrl] | None
signup: datetime | None
@computed_field
@property
def current_age(self) -> int:
return datetime.date.today().year - self.birth_date.year
Utilisons notre nouveau modèle
Maintenant que nous avons un modèle, essayons de l’utiliser en nous fondant sur des données externes au format le plus commun du développement web : le json.
external_data = {
"id": "20CCF8B8-8EAA-4324-99FC-7512A5FB5D00",
"name": "Jar Jar Binks",
"email": "jar.jar@binks.com",
"birth_date": "1995-06-31",
"websites": ["jarjar.binks.com", "jjb.star-wars.com"]
}
user = User(**external_data)
print(user.id)
#> 20CCF8B8-8EAA-4324-99FC-7512A5FB5D00
print(user.current_age)
#> 18
print(user.model_dump())
#> {
#> "id": "20CCF8B8-8EAA-4324-99FC-7512A5FB5D00",
#> "name": "Jar Jar Binks",
#> "email": "jar.jar@binks.com",
#> "birth_date": "1995-06-31",
#> "websites": ["jarjar.binks.com", "jjb.star-wars.com"]
#> }
La principale propriété de Pydantic à remarquer est la coercition de types : pour un type cible, Pydantic sait comment convertir le type donné en entrée. Si l’on désire à la fin un entier, on peut fournir en entrée un entier, une chaine de caractère, un nombre flottant, etc. Ceci est particulièrement pratique pour parser des dates par exemple (ici on fournit une chaine de caractères qui est convertie en objet python datetime)
La validation des erreurs en elle même
Voici un exemple concret de ce que nous renvoie Pydantic lorsque les données en entrée ne sont pas conformes :
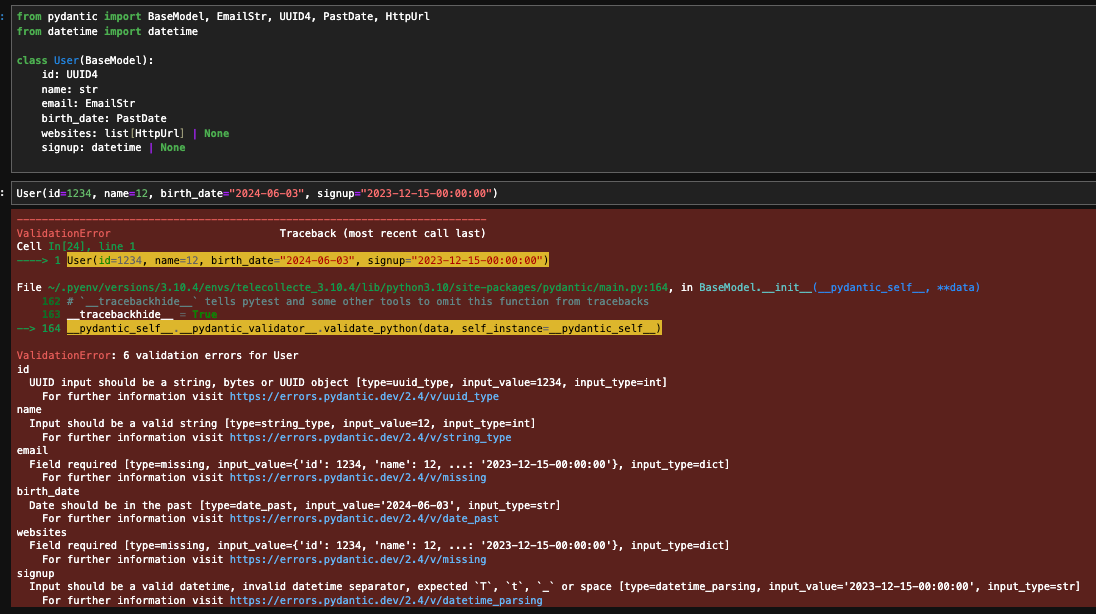
Quelques conclusions par rapport à cet exemple :
- Pydantic détecte plusieurs erreurs possibles
- la variable n’a pas le bon type (et ne peut être convertie) : entier au lieu de string/UUID pour le champ
ID. - le contenu de la variable n’est pas conforme :
birth_dateest une date dans le futur, la date passée n’a pas le bon format. - la variable est manquante : nous n’avons pas rempli le champ
websites. On peut cependant facilement ajouter des valeurs par défaut pour nos champs (websites: list[HttpUrl] | None = None) de la même façon qu’on le ferait pour un paramètre d’une fonction.
- la variable n’a pas le bon type (et ne peut être convertie) : entier au lieu de string/UUID pour le champ
- Les messages d’erreurs sont clairs et nous indiquent :
- le type et la valeur donnés en entrée
- le type et la valeur attendus
- un message d’erreur en anglais pour savoir comment corriger le problème
En plus de nous apporter de la rigueur, Pydantic nous renvoie donc des messages d’erreur compréhensibles et complets facilitant la correction.
Des usages concrets chez Deepki ?
Développement web
Pour développer des API propres et fiables, une tâche ô combien courante dans notre métier aujourd’hui, Pydantic se démarque.
En convertissant sans effort des dictionnaires désordonnés, des blobs ou chaînes de caractère JSON ou encore des résultats aux formats très différents de diverses bases de données en objets python entièrement validés, avec des rapports d’erreurs précis, Pydantic permet aux développeurs de garder leur API simple et lisible dès le départ.
Les modèles peuvent être imbriqués, réutilisés et librement combinés pour capturer élégamment l’essence de n’importe quelle entité de notre domaine.
Interface entre notre API et notre base de données
Aujourd’hui, il n’est pas rare qu’une application web se connecte à de multiples bases de données. Chacune de ces bases de données et leur clients adaptés à notre langage fournissent des interfaces et des formats de réponse différents. Nous enlevons aujourd’hui plus facilement cette charge mentale au développeur. Nous avons pris le parti dans mon équipe de regrouper tous nos accès à nos bases de données dans un même module (cf repository pattern). Il ne renvoie que des instances de modèles entièrement validées par Pydantic.
# Représentation métier de notre utilisateur
class UserModel(BaseModel):
name: str
...
signup: datetime
last_login: datetime
password: password
# Représentation des champs possibles pour créér une requête
class UserQuery(BaseModel):
name: list[str]
last_login: datetime | None = None
class UserMongoRepository():
def create_one(self, new_user: UserModel) -> None:
self.collection.insert_one(new_user.model_dump())
def find_one(self, filters: UserQuery | None = None) -> UserModel | None:
doc = self.collection.find_one(filters)
return UserModel(**doc) if doc else None
def find_all(self, filters: UserQuery | None = None) -> Iterator[UserUserModel]:
docs = self.collection.find(filters)
return (UserModel(**doc) for doc in docs)
def delete_many(self, filters: UserQuery) -> int:
result = self.collection.delete_many(filters)
return result.deleted_count
def count(self, filters: UserQuery) -> int:
return self.collection.count_documents(filters)
- Toutes les interactions/spécificités de notre base de données, ici MongoDB, ne sont présentes qu’à un seul endroit. Ceci a la vertu de rentre triviale la recherche de code interagissant avec notre collection et faciliterait grandement une migration vers une autre base de données si nécessaire.
- Hors de ce module, le code métier n’utilise que du Python standard avec les modèles de données définis via Pydantic. Tout est typé et validé. Il est donc maintenant impossible d’insérer des données en base ne passant pas la validation de Pydantic. Ceci peut nous éviter des corruptions de la base de données et des migrations pénibles. Enfin, nous récupérons uniquement des objets que nous connaissons, pas de spécificité de notre base de données dans le reste du code.
Input/Output d’un endpoint d’API
Voici un exemple concret (avec Flask ici) de la validation des données en entrée et sortie d’un endpoint HTTP :
# Représentation métier de notre utilisateur
class User(BaseModel):
id: UUID4
name: str
email: EmailStr
birth_date: PastDate
websites: list[HttpUrl] | None
signup: datetime | None
# Validation du contenu de la requête entrante
class CreateUserRequest(BaseModel):
name: str = 'Jar Jar Binks'
age: PositiveInt
email: EmailStr
birth_date: PastDate
website: HttpUrl | None
# Validation de la réponse de l'endpoint
class CreateUserResponse(BaseModel):
created_user: User
creation_date: datetime
@admin_blueprint.route("/create-user", methods=["POST"])
def create_user():
try:
req = CreateUserRequest(**request.json)
except ValidationError as e:
# En cas d'erreur de validation, on renvoie une erreur 400 avec un message d'erreur explicite
raise BadRequest(format_Pydantic_validation_error(e))
# Logique interne de l'endpoint
user: User = create_user()
# Création et validation de la réponse
response = CreateUserResponse(user)
# Sérialisation JSON de la réponse
# Nous pouvons même choisir certains champs imbriqués à exclure de la réponse
return response.model_dump_json(exclude={'user': {'websites', 'signup'}}), 201
Nous voyons beaucoup de choses dans cet exemple :
- création très explicite et compréhensible de modèles représentant notre entrée et sortie de l’endpoint.
- Une gestion des erreurs entièrement encapsulée par Pydantic. Nous n’avons qu’à générer notre réponse HTTP en incluant le message d’erreur généré.
- Une sérialisation JSON intégrée des données renvoyées par l’endpoint.
De mon point de vue, le développeur a ici beaucoup gagné :
- le temps de développement est drastiquement réduit, plus besoin de valider à la main toutes les entrées grâce aux nombreux types fournis par Pydantic pour valider la donnée (
email,URL, entier positif, etc..) - On se concentre sur la logique métier, en ayant accès à des données typées et validées en lesquelles nous avons confiance.
Plugins et ecosystèmes
Des interactions avec des ORMs
Pour des développeurs ayant de l’attrait pour l’utilisation d’ORMs, Pydantic s’intègre très bien avec eux pour lier des modèles de base de données avec notre code python. Un exemple ici avec le très populaire SQLAlchemy.
Intégration par défaut sur les nouveaux frameworks
Parmi les évolutions de framework web dans le monde de Python, FastAPI génère une forte traction. Un de ses forts partis pris est d’utiliser par défaut Pydantic pour la création d’APIs web. De ceci découle une des fonctionnalités les plus attirantes du framework : la documentation de l’interface est entièrement auto générée et synchronisée avec la base de code.
Performance
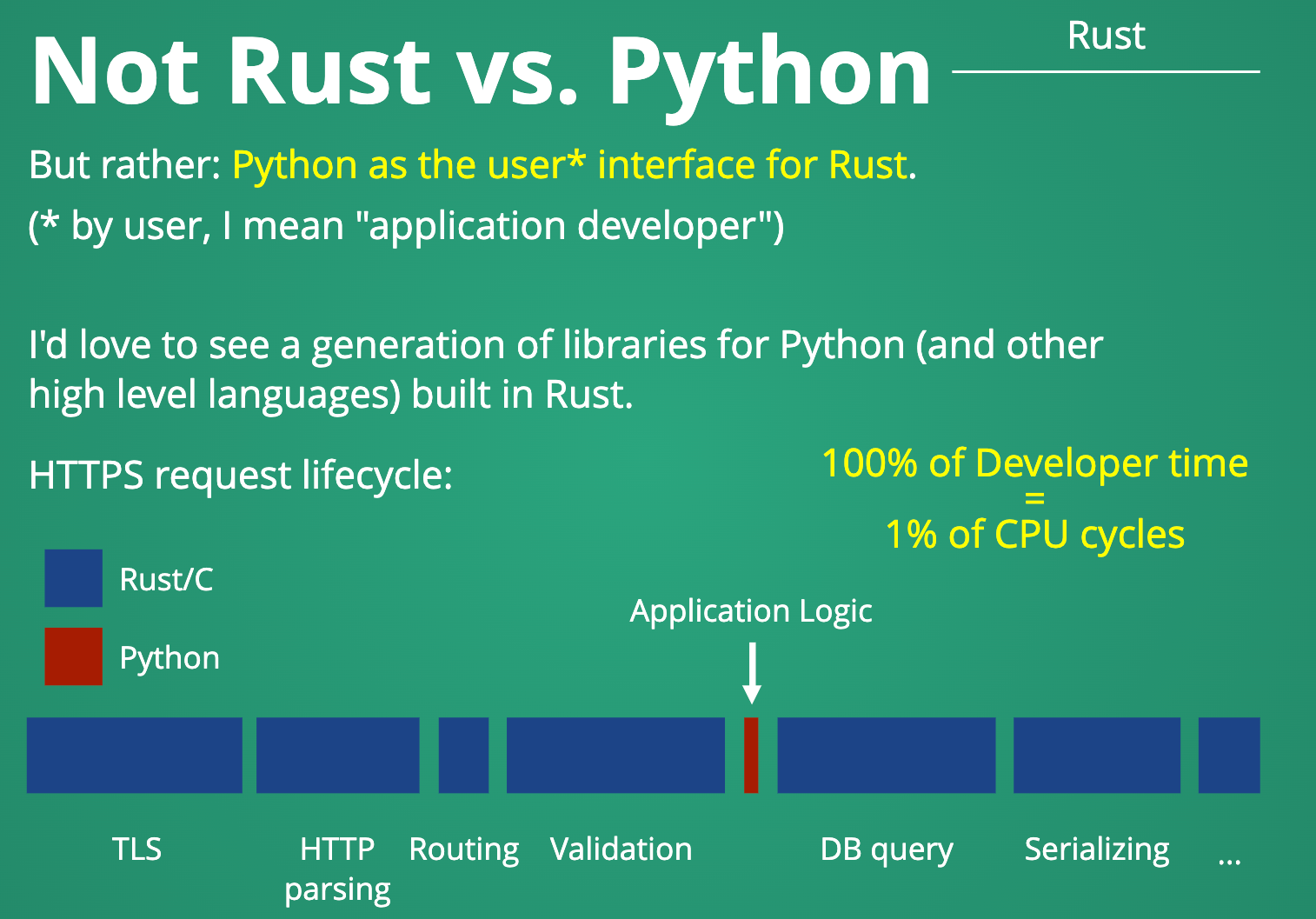
Pydantic a, à mon avis, réussi un pari très inspirant en mêlant un des attraits les plus forts de Python, son expérience utilisateur, à la performance et stabilité, en implémentant le cœur de la librairie en Rust.
Qu’est ce que Pydantic n’est pas ?
Cet article est fortement influencé par mon opinion, il faut cependant comprendre que Pydantic répond à certains objectifs et ne doit pas être utilisé partout et tout le temps.
-
Pydantic n’a pas pour ambition de remplacer toutes les fonctionnalités Python pour faire de l’orienté objet. Il apporte seulement de la validation de donnée en reprenant les syntaxes existantes.
-
En ajoutant de la validation via nos modèles, nous dégradons partiellement la performance de notre service. En effet, si je déclare et type une variable comme une liste d’entiers et essaye de valider celle ci sur 100.000 entiers, cela aura forcément un impact sur la durée d’exécution de nos fonctions.
-
Les données ne sont validées qu’à l’instanciation d’un modèle. En cas de changement, Pydantic ne vérifie pas les modifications entrantes. Un contournement est possible en ajoutant une option de configuration de notre modèle.
Qu’est ce que ça change pour Python ?
La bibliothèque Pydantic est à mon avis un événement qui change la donne pour Python et son écosystème. En effet, elle apporte rigueur et robustesse à la gestion des données d’une manière élégante et intuitive qui manque aujourd’hui. Élegante et intuitive car elle ne s’appuie que sur des pratiques déjà connues et adoptées par les développeurs python (le typage, l’orienté objet).
Les développeurs Python peuvent désormais construire leurs applications sur des bases plus fiables et prédictibles. Rigueur au niveau des types, validation des entrées, gestion d’erreur précise : Pydantic automatise ce qui est souvent fait à la main, qui induit souvent des erreurs humaines. Cette bande passante libérée pour le développeur lui permet de son concentrer uniquement sur son cœur de métier.
Enfin Pydantic répond très bien à l’enjeu de conjuguer performance, stabilité et expérience développeur et ceci montre la direction que pourraient prendre beaucoup de librairies dans le futur à mon avis (bonjour Pandas). Je pense sincérement que l’intégrer au noyau cœur du langage Python serait bénéfique pour toute la communauté.
Cette entrée a été publiée dans programmation avec comme mot(s)-clef(s) programmation, python, qualité
Les articles suivant pourraient également vous intéresser :
- La bonne et la mauvaise review par Sébastien Bizet
- Dark mode vs Light mode : accessibilité et éco-conception par Jean-Baptiste Bergy
- Principes SOLID et comment les appliquer en Python par Mariana ROLDAN VELEZ
- Comment utiliser les fixtures pytest en autouse tout en maîtrisant ses effets de bord ? par Amaury Boin
- Améliorer l'architecture d'une application Vue grâce à la composition API par Pierre Assemat
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.