Débuter avec Ansible
![]()
La gestion de l’infrastructure est l’un des process les plus importants du développement logiciel.
Contrairement à la gestion d’infrastructure traditionnelle, l’infrastructure programmable (ou Infrastructure as code IaC) consiste à automatiser le provisionnement,
la configuration et le déploiement uniquement via du code, souvent sous forme de fichiers de configuration ou de scripts.
L’avantage de l’IaC est de réduire les interventions humaines, de minimiser les erreurs, ainsi que d’augmenter l’agilité de l’équipe en lui facilitant la création, le déploiement et la surveillance des applications.
Plusieurs solutions ont été développées pour automatiser le déploiement des serveurs d’une infrastructure, telles que Terraform ou AWS CDK pour la création des serveurs dans un environnement cloud, et puppet, chef ou Ansible pour la configuration.
Dans cet article, nous allons découvrir Ansible, son fonctionnement et les notions de bases pour débuter avec cet outil.
Ansible
Ansible est un logiciel open source qui permet de gérer la configuration des serveurs et le déploiement d’applications à distance. Il a été créé en 2012 par Michael DeHaan, puis il a été racheté par Red Hat en 2015.
Ansible fonctionne en mode push. Ce mode consiste à contrôler les serveurs (nodes) depuis un poste local qu’on appelle un node manager ou un control node.
Le node manager doit être une machine UNIX disposant d’une version d’Ansible installée.
Une fois Ansible installé sur cette machine, les tâches à exécuter sont écrites dans des fichiers de configuration en yaml, ces tâches sont converties par Ansible vers des modules python, puis sont poussées grâce à une connexion SSH pour être exécutées sur les serveurs distants.
La connexion SSH est maintenue jusqu’à ce que les tâches soient totalement exécutées et que les résultats soient renvoyés vers le node manager.
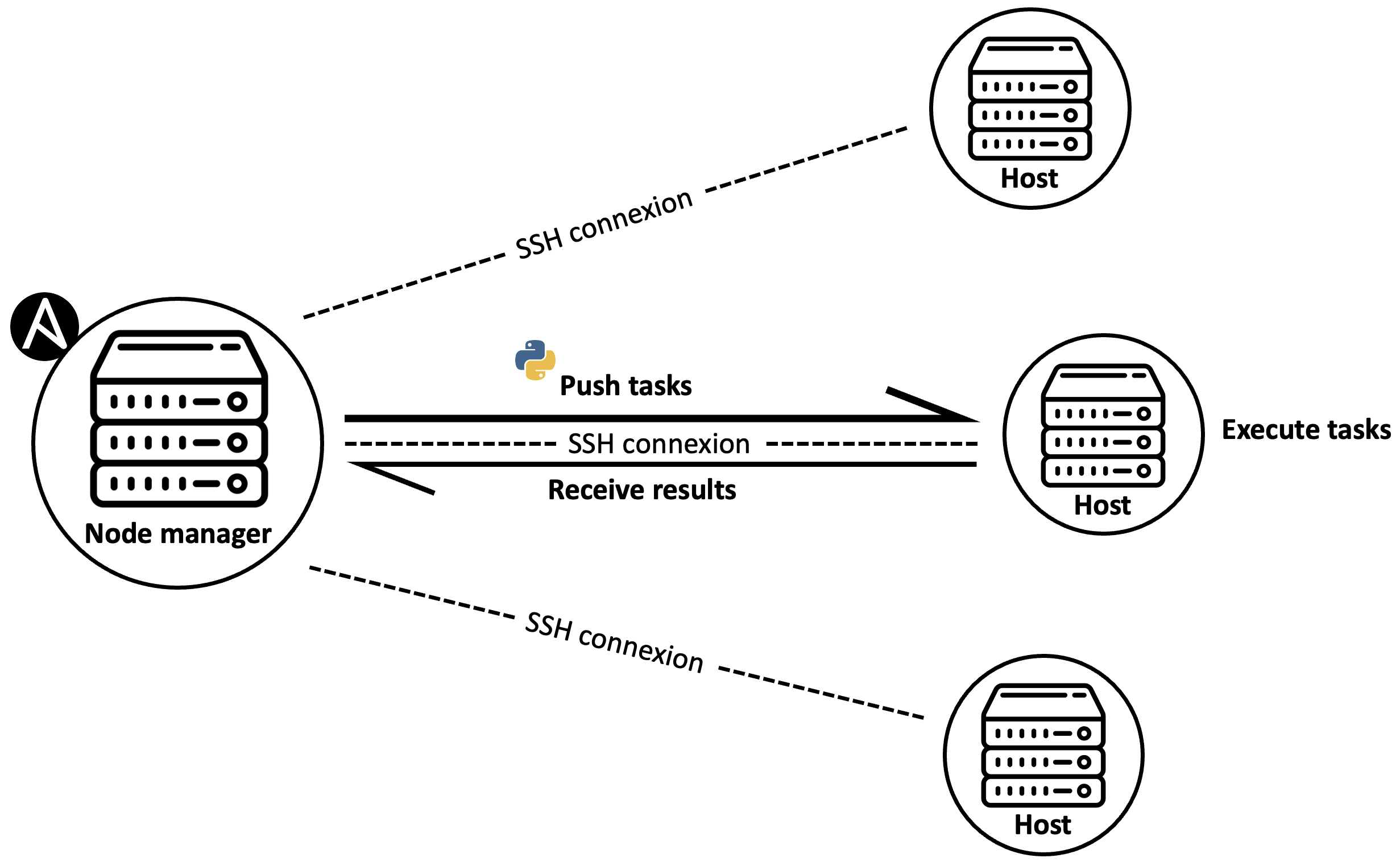
Remarque : Dans certains cas, Ansible peut aussi être utilisé en mode pull. Dans ce mode, Ansible doit être installé sur tous les serveurs, et chacun de ces serveurs “tire” les fichiers de configuration depuis un repository distant pour les convertir en tâches et les exécuter.
Inventaire
Avant de configurer les tâches, il est nécessaire de définir l’inventaire Ansible. Il s’agit de l’ensemble des serveurs qu’on souhaite gérer. L’inventaire peut contenir un ou plusieurs serveurs. On peut regrouper ces serveurs dans des sous-groupes pour en faciliter la gestion.
Le but de l’inventaire est de pouvoir cibler les serveurs pour lesquels les tâches Ansible seront exécutées, ainsi que de définir des variables pour chaque serveur.
Il est possible de définir les serveurs de trois manières :
- un fichier INI statique,
- un fichier YAML statique,
- un script qui génère l’inventaire sous forme de JSON d’une manière dynamique.
Les deux premières méthodes statiques sont à privilégier quand on dispose de serveurs physiques. En revanche, le script dynamique est très recommandé pour lister les serveurs virtuels créés dans un cloud.
Exemple de fichier INI :
web_1 ansible_host=35.1.1.1
web_2 ansible_host=35.1.1.2
lb ansible_host=35.1.1.3
db ansible_host=35.1.1.4
[webs]
web_1
web_2
[dbs]
db
[lbs]
lb
Dans l’exemple ci-dessus, l’inventaire contient 2 serveurs web, un serveur load balancer et un serveur database.
Les serveurs web appartiennent au groupe webs, et les serveurs load balancer et database appartiennent respectivement aux groupes lbs et dbs.
Modules
Ansible fournit plus de 3000 modules qui permettent d’exécuter des tâches sur chaque serveur.
La commande ansible-doc -l liste l’ensemble de ces modules.
Ansible fournit aussi une documentation détaillée pour chaque module via la commande ansible-doc <module>.
Chaque module peut être exécuté sous forme d’une tâche. Cette dernière est définie par :
- sa configuration (un ensemble de paramètres qui ne dépendent pas du module),
- le module Ansible choisi,
- la configuration du module (un ensemble d’arguments propre au module).
Les tâches peuvent être lancées grâce aux deux commandes suivantes : ansible et ansible-playbook. Nous les détaillons ci-après :
La commande ansible
C’est la commande qui permet de lancer une seule tâche en mode ad-hoc sur un ou plusieurs serveurs. Ce mode est principalement utilisé sur des environnements de développement pour faire des tests ou pour se familiariser avec des nouveaux modules.
On peut l’utiliser ponctuellement en production pour exécuter des tâches non répétitives.
La commande ad-hoc se lance de cette manière :
ansible <PATTERN> -i <INVENTORY> -m <MODULE_NAME> -a <MODULE_ARGS> -b
l’argument pattern permet de définir le nom du serveur ou le groupe de serveurs sur lesquels la tâche sera lancée.
En plus de cet argument principal, on trouve les arguments optionnels suivants :
-iou--inventory: le chemin vers le fichier de l’inventaire,-mou--module-name: le nom du module Ansible,-aou--args: l’ensemble des clés/valeurs pour paramétrer le module,-bou--become: Certains modules nécessitent des droits pour être exécutés. Dans ce cas, ce paramètre doit être rajouté pour l’élévation des privilèges (sudo).
La commande ansible-playbook
Contrairement à la commande ad-hoc, ansible-playbook permet de lancer un ensemble de tâches codées dans un ou plusieurs fichiers yaml, et destinées à être exécutées de manière répétée en production.
Dans la suite de cet article, nous verrons en détail ce qu’est un playbook, les éléments qui le composent et comment ils sont structurés dans un projet.
Exemples
Le module debug
On commence les exemples par le module debug, un module très utile pour déboguer des variables et tester des conditions au milieu d’un playbook.
ansible localhost -m debug -e "my_name=John" -a "msg='My name is {{ my_name }}'"
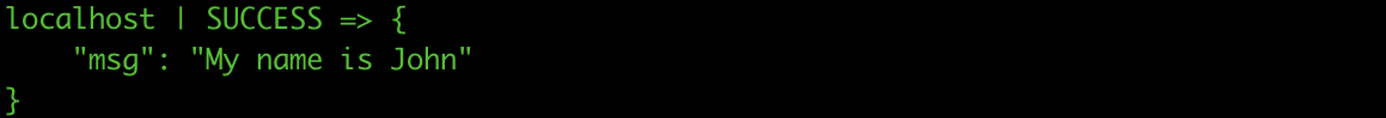
Le serveur ciblé par cette tâche n’est pas un serveur distant, il s’agit juste du poste de travail local, qui est rajouté automatiquement par Ansible dans l’inventaire.
Dans cette tâche, l’argument -e (ou --extra-vars) est utilisé pour définir la variable my_name.
Cette dernière est bien interprétée dans le message affiché grâce au système de template jinja2.
Le module shell
Le module shell donne la possibilité de lancer des commandes shell.
Dans cet exemple, nous créons un nouveau dossier ansible_directory en lançant la commande bash mkdir ansible_directory.
ansible localhost -m shell -a "mkdir ansible_directory"
Bien qu’il soit difficile de connaître tous les modules disponibles sur Ansible, il est conseillé d’explorer la collection des modules afin de trouver celui qui répond au besoin au lieu de tout faire en bash.
Si on reprend l’exemple de création d’un nouveau dossier, il est possible d’exécuter cette tâche en utilisant le module file qui permet la gestion des fichiers et des dossiers.
ansible localhost -m file -a "path=ansible_directory state=directory"
En plus de ce module, on trouve aussi le module copy qui copie un fichier depuis la machine locale vers un serveur distant, ainsi que le module template qui permet de générer un fichier dynamiquement avec Jinja2.
Playbook
Un playbook est une séquence de plusieurs jeux d’instruction (ou play) définis dans un fichier yaml.
Chaque play contient lui-même un ensemble de tâches et une liste de serveurs ciblés par ce play.
Lors de l’excécution d’un playbook, les play sont excécutés dans l’ordre de haut en bas.
Les tâches de chaque play sont également lancées dans cet ordre.
La liste des serveurs associés peut changer d’un play à l’autre. Par exemple, dans un playbook qui permet l’installation d’une application, on peut imaginer un premier play qui effectue des installations communes de packages sur tous les serveurs, un deuxième play pour la configuration des serveurs de base de données et puis un troisième pour les serveurs Web.
Le playbook est lancé grâce à la commande ansible-playbook, elle prend comme argument le nom de fichier du playbook.
Cette commande accepte des arguments optionnels tels que les paramètres --inventory et --extra-vars vus précédemment,
mais elle n’accepte pas certains paramètres comme le pattern et le --args car ils sont définis au niveau de chaque play.
Exemple
Si on veut afficher à nouveau le contenu d’une variable my_name dans un message en passant par un playbook, on doit suivre les étapes suivantes :
1- Créer un nouveau fichier yaml playbook_debug.yml à la racine du projet.
2- Dans ce fichier yaml, définir un play "My first play" avec une seule tâche debug.
- name: My first play
hosts: localhost
vars:
my_name: John
tasks:
- name: Display my name
debug:
msg: 'My name is {{ my_name }}'
Les paramètres du play utilisés sont :
name: le nom du play courant, ce nom n’est utilisé que dans le code de retour pour pouvoir repérer facilement les logs associés à ce play,hosts: définition des serveur ou des groupes de serveurs ciblés par les tâches du play,vars: définition des variables,tasks: liste des tâches du play.
3- Lancer la commande :
ansible-playbook playbook_debug.yml
Résultat
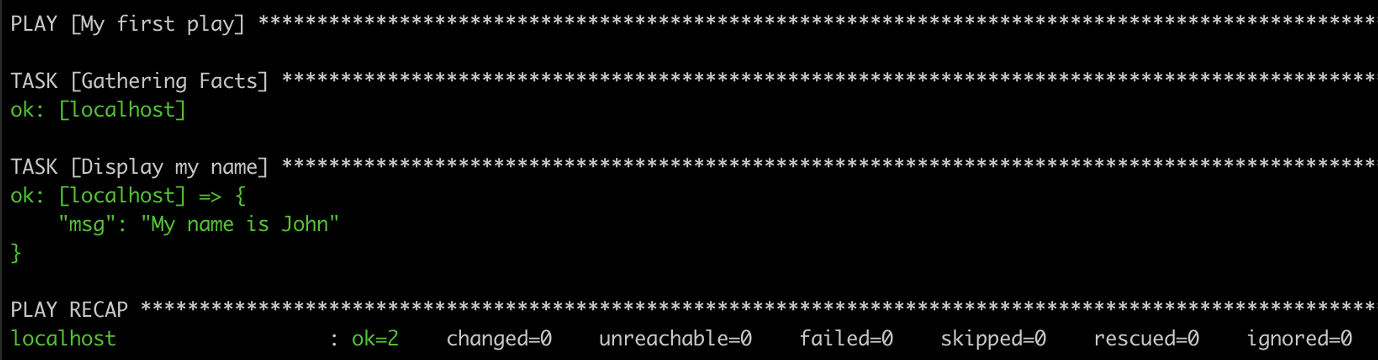
Le code de retour affiche le nom du play suivi des noms des tâches lancées.
En plus de notre tâche Display my name, on remarque qu’Ansible a exécuté une deuxième tâche appelée Gathering Facts non définie dans le play.
Il s’agit de la tâche lancée par defaut au début de chaque play. Elle utilise le module setup qui permet de récupérer des variables utiles pour chacun des serveurs définies dans le paramètre hosts.
Rôles
Dans un grand projet, on peut se retrouver face à plusieurs playbooks ayant beaucoup de play et avec des centaines de tâches dedans. Dans ce genre de projets on risque de perdre en lisibilité et de dupliquer des bouts de configuration dans les différents play / playbooks.
Le rôle est une notion Ansible qui permet de pallier ces problèmes. Il consiste à grouper logiquement un ensemble de tâches sous forme de composants réutilisables dans différents playbooks.
Par exemple, la logique de configuration des serveurs de base de données peut être encapsulée dans un rôle db.
Ce rôle peut être appelé dans plusieurs playbooks afin d’installer les bases de données pour toutes les applications gérées par le projet.
Structure d’un rôle
Chaque rôle est mis dans un dossier à part. L’ensemble de ces dossiers sont groupés dans un dossier parent appelé roles qui se trouve à la racine du projet.
Voici un exemple de structure d’un rôle:
roles/
my_first_role/
default/
main.yml
vars/
main.yml
tasks/
main.yml
meta/
main.yml
handlers/
main.yml
files/
file1.txt
file2.sh
templates/
template.j2
La présence de tous ces répertoires n’est pas obligatoire, mais leur structure est bien définie et doit respecter certaines règles :
- Certains répertoires doivent contenir au moins un fichier yaml nommé
main.yml - Le contenu et l’utilité des fichiers yaml changent en fonction du répertoire :
default: sert à définir des variables statiques,vars: sert à définir des variables qui ont tendance à être modifiées par l’utilisateur (un numéro de version par exemple),tasks: le répertoire le plus utilisé dans un rôle, il permet de définir ses tâches principales,meta: permet de définir les métadonnées du rôle. Parfois, l’exécution de certaines tâches (ou rôles) est requise avant de lancer les tâches d’un rôle (installation de dépendances / vérifications …). Dans ce cas, elles sont déclarées ici.handlers: on peut abonner les tâches d’un rôle à deshandlers. Ces derniers seront lancés automatiquement si ces tâches sont exécutées.
L’exemple de handler le plus récurrent est le redémarrage d’un service nécessaire après l’exécution de certaines tâches.files: contient les fichiers à déployer par le rôle.templates: contient les templates jinja2 à déployer par le rôle.
- Le nom du rôle correspond au nom du dossier qui le contient.
Par exemple, on peut nommer le rôle
my_first_roledans un play de la manière suivante :
- name: My first play
hosts: all
roles:
- role: my_first_role
Variables
Les variables Ansible sont divisées en deux types :
Les facts
Les données associées aux serveurs et récupérées via la tâche gathering facts tels que l’adresse IP ou le système d’exploitation.
Les variables définies dans le code
Jusqu’à maintenant, on a eu l’occasion de voir 3 manières pour définir une variable :
- Dans la section
varsd’un play, - Dans les dossiers
default/varsd’un rôle, - Dans l’argument
--extra-varsde la commandeansible-playbook.
Il existe en tout une vingtaine de manières différentes de définir une variable dans Ansible !
Ansible priorise la définition des variables selon un ordre bien défini (cf. la documentation sur les priorités des variables Ansible).
D’après cette documentation, on voit que les extra-vars sont les plus prioritaires. Ceci est pratique quand on souhaite forcer une variable (un numéro de version par exemple) lors du lancement d’un playbook.
Codes de retour
On a vu précédemment qu’Ansible maintient la connexion SSH entre le node manager et les serveurs distants pour récupérer les résultats. Ces derniers sont affichés sous forme de logs.
Dans les logs on voit principalement les tâches qui ont été lancées et leur status d’exécution.
Les différents status qu’on retrouve en sortie d’Ansible sont :
Ok: la tâche a été lancée mais elle n’a pas changé l’état du serveur distant,Changed: la tâche a été lancée et elle a changé l’état du serveur distant,Unreachable: le serveur distant est inaccessible,Failed: la tâche a échoué,Skipped: la tâche n’a pas été lancée,Rescued: un bloc de tâches a été lancé à la suite d’une erreur au niveau d’un autre bloc de tâches,Ignored: la tâche a échoué mais l’erreur a été ignorée.
Exemple
Prenons l’exemple du play suivant:
- name: Ansible output
hosts: localhost
tasks:
- name: Task 1
file:
args:
path: ansible_directory
state: directory
when: false
- name: Task 2
file:
args:
unsupported_parameter: unsupported_parameter
ignore_errors: true
- name: Task 3
file:
args:
path: ansible_directory
state: directory
- name: Task 4
file:
args:
path: ansible_directory
state: directory
- name: Task 5
file:
args:
invalid_argument: invalid_argument
En lançant un ansible-playbook, on obtient les résultats suivants:
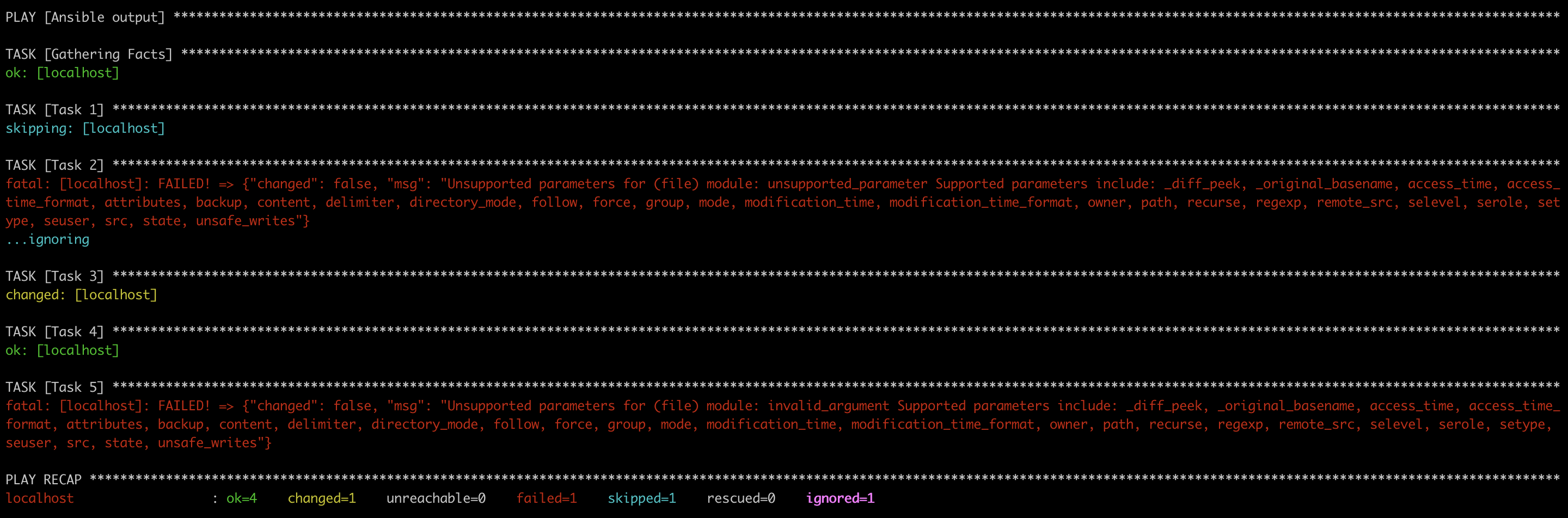
- La tâche 1 n’a pas été exécutée parce qu’elle est conditionnée par le paramètre
whenqui prend toujours la valeurfalse. Il doit prendre une valeurtruepour que cette tâche soit lancée. - La tâche 2 a échoué à cause d’un mauvais paramètre
unsupported_parameter, mais l’erreur a été ignorée grace au paramètreignore_errors: true. - La tâche 3 a été lancée avec succès. Le status
changedveut dire que le dossier vient d’être créé par cette tâche. - La tâche 4 a également été lancée avec succès. Mais le status
Okveut dire que le dossier existait déjà et que cette tâche n’a rien changé. - La tâche 5 a échoué à cause d’un mauvais paramètre
invalid_argument.
Remarques
- Pour une meilleure lisibilité des logs, il faut que les noms des tâches soient explicites.
Une tâche qui s’appelleCreate fileet qui renvoie le statusOknous donne l’impression que le fichier a été créé. Par contre, si on la nommeEnsure file is created, on gagne en lisibilité. - Pour afficher plus d’informations sur les logs, on peut activer deux niveaux de verbosité en passant l’un des deux paramètres
-vou-vvvdans la commandeansible-playbook.
Conclusion
Chez Deepki, Ansible est utilisé pour automatiser la configuration de nos plateformes et le déploiements de nos applications.
L’automatisation de ces aspects nous offre une grande flexibilité et nous permet de répondre aux besoins de nos clients dans de brefs délais et d’une manière sécurisée.
Le but de cet article est de présenter cet outil et de découvrir ses notions de base.
Il existe d’autres notions plus poussées que nous n’avons pas eu l’occasion de voir et qui seront présentées et détaillées dans de prochains articles.
Cette entrée a été publiée dans programmation avec comme mot(s)-clef(s) DevOps, Ansible, Infrastructure as code, IaC
Les articles suivant pourraient également vous intéresser :
- La bonne et la mauvaise review par Sébastien Bizet
- Dark mode vs Light mode : accessibilité et éco-conception par Jean-Baptiste Bergy
- Principes SOLID et comment les appliquer en Python par Mariana ROLDAN VELEZ
- Pydantic, la révolution de python ? par Pablo Abril
- Comment utiliser les fixtures pytest en autouse tout en maîtrisant ses effets de bord ? par Amaury Boin
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.