Domain Driven Design - Définir et modéliser un domaine métier
Dans le monde du développement logiciel, les développeurs ont toujours intérêt à écrire un code simple, lisible, maintenable et facilement évolutif. Pour ce faire, plusieurs approches du développement ont été élaborées pour définir des règles et des bonnes pratiques à suivre afin de construire une architecture solide et pérenne.
En 2003, Eric Evans a publié un livre intitulé “Domain-Driven Design, Tackling complexity in the Heart of Software”. Cet ouvrage est la synthèse d’une vingtaine d’années d’expérience sur le développement des systèmes informatiques. L’approche du Domain Driven Design selon Eric Evans consiste à associer le design d’une application au domaine métier et à fonder sa conception sur les règles et la logique de ce domaine.
Dans cet article, nous allons mettre l’accent sur la définition et la modélisation du domaine selon l’approche Domain Driven Design, que nous appelerons DDD dans la suite de cet article.
Une architecture en couches
Avant de parler du domaine, il faut savoir qu’une application n’est pas composée que de code métier. Eric Evans découpe l’architecture logicielle d’une application en 4 couches :
-
Couche interface utilisateur : La partie de l’application qui permet d’afficher les rendus visuels à l’utilisateur et lui permet d’interagir.
-
Couche application : Une couche fine qui coordonne les interactions avec la couche domaine. Elle peut par exemple vérifier les accès des utilisateurs, sérialiser les données échangées et valider leur format.
-
Couche domaine : C’est le cœur de l’application qui représente le métier et regroupe ses règles. C’est cette couche que nous allons détailler dans la suite de l’article.
-
Couche infrastructure : Cette couche sert principalement à fournir des outils pour établir des liens entre les différentes couches.
Bâtir la connaissance du domaine
Nous allons nous appuyer sur un exemple concret vécu au sein de Deepki, un retour d’expérience sur le développement d’une nouvelle fonctionnalité en s’appuyant sur l’approche DDD.
Avant de commencer une nouvelle fonctionnalité, il est nécessaire d’avoir un contexte clair, ce qui nous aidera à prendre facilement des décisions plus pertinentes au fur et à mesure de l’avancement du code.
Le contexte cette fois-ci était autour des grilles tarifaires. Ce sont les grilles de prix d’abonnement et de consommation d’énergie négociées entre nos clients et leurs fournisseurs d’énergie. La nouvelle fonctionnalité grilles tarifaires permettra à nos clients de saisir et modifier ces grilles à travers l’application Deepki Ready.
Le project manager joue un rôle très important pour que le besoin soit clair et que l’information soit partagée entre les experts métiers et les développeurs. Il commence par recueillir les besoins auprès des chefs de projets, il rédige ensuite une spécification qui synthétise ces besoins et qui regroupe l’ensemble des règles métier. Finalement, il organise et anime des ateliers avec les développeurs pour présenter cette synthèse tout en s’assurant que le besoin et les règles métier soient bien clairs pour les développeurs.
Cette étape est primordiale dans la construction de la connaissance du domaine, donc il n’y a pas de DDD sans des experts métier. C’est vrai que cela demande d’y investir du temps, mais ce n’est pas du temps perdu car cela nous permettra de produire un code robuste et de pouvoir le faire évoluer facilement plus tard si besoin.
Voici quelques règles retenues lors de ces ateliers :
- Un tarif contient les prix de capacités et de consommations en kWh.
- Chaque tarif a une date de début et une date de fin.
- Pour chaque fluide, il existe plusieurs types de tarifs possibles, chacun de ces types est appelé pricing.
- La différence entre ces pricings est le nombre de tranches tarifaires :
- Une tranche (base).
- Deux tranches (heures creuses / heures pleines).
- 4 tranches (heures creuses hiver / heures pleines hiver / heures creuses été / heures pleines été).
- 5 tranches (heures creuses hiver / heures pleines hiver / heures creuses été / heures pleines été / heures de pointe).
- Pour chaque pricing, et pour chaque tranche tarifaire associée, il y a un prix de consommation et un prix de capacité négocié. Ce sont des propriétés de pricing.
- Chaque tarif est négocié pour un ensemble de compteurs ayant le même fluide. Cet ensemble est appelé lot dans le langage métier.
Faisons un schéma pour illustrer et mieux comprendre ces règles :
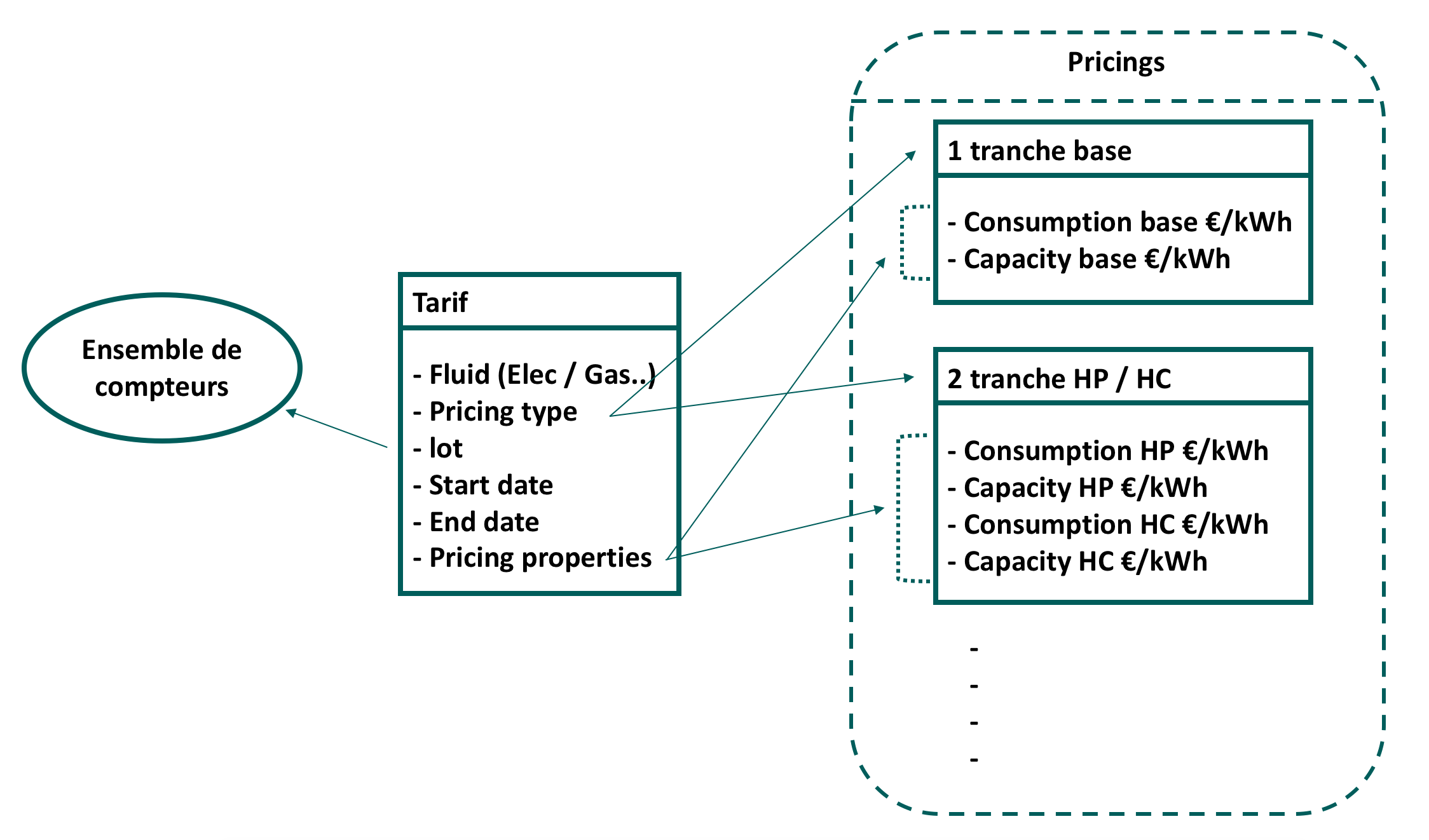
Modéliser le domaine
À partir de tous ces éléments, nous allons essayer de modéliser notre domaine tarif.
Bien que les tarifs seront la base des calculs pour d’autres fonctionnalités de l’application Deepki Ready, à savoir le contrôle des anomalies de factures et l’estimation du budget de consommation énergétique des années passées et futures, le domaine des tarifs sera contenu dans un modèle propre à lui. Nous ne devons donc en aucun cas gérer les tarifs en dehors de ce modèle. Le but derrière cette règle est d’avoir un code métier découplé, ce qui limite et facilite la modification et l’évolution du code lorsque de nouvelles exigences métier associées à ce domaine arrivent.
Langage partagé (Ubiquitous language)
Vous avez bien remarqué que quand j’ai listé les règles métier, j’ai insisté sur le nom de chaque élément. Lors de la modélisation les mêmes nomenclatures doivent être employées. Tarif, Lot, Pricing… sont tous des termes qui devront être partagés entre les développeurs et les experts métier. L’idée c’est de s’assurer que l’on partage un vocabulaire commun afin de faciliter la collaboration et d’éviter toute sorte de confusion entre les différentes parties prenantes.
Une bonne façon de vérifier que ce principe a bien été respecté est de voir si un expert métier reconnait les noms utilisés pour nommer les variables et les classes du modèle métier dans notre code.
Entités (Entities)
Nous allons représenter chaque tarif sous forme d’entité.
Une entité c’est un objet qui a, en plus de ses attributs, une identité unique, et qui vivra tout au long de la durée de vie du système. Dans notre exemple, ce n’est pas possible d’avoir un même tarif négocié et signé deux fois entre notre client et son fournisseur d’énergie, et c’est pour ça qu’on ne doit pas insérer des doublons de ce tarif dans notre base de données. Lors de la création d’un nouveau tarif, nous ne pouvons pas l’identifier que par sa période, ni par ses propriétés de pricing. Dans ce cas, nous pouvons créer une clé unique et l’associer à ce tarif pour éviter toute création de doublon.
Objets-Valeurs (Value Objects)
Les objets entité sont eux même constitués d’un ou plusieurs objets. Ces derniers n’ont pas forcement une identité propre, ils se contentent de porter une valeur immutable. Ce sont des objets-valeurs (ou value objects en anglais). Si on reprend l’exemple de l’entité tarif, le prix de chaque propriété de pricing est un objet-valeur. Ce prix n’est pas unique dans l’application parce qu’on peut trouver plusieurs propriétés de pricing qui ont le même prix. Bien que l’entité tarif a une identité, ces propriétés de pricing sont susceptibles de changer dans le temps dans le cas d’une renégociation par exemple. Dans ce cas, on écrase les anciens objets-valeurs de ces propriétés et on crée des nouveaux avec les bons prix.
Nous donnons un exemple de dataclass qui définie les entités Tariff, ainsi qu’une class de type NamedTuple pour définir les objets-valeurs Price:
from dataclasses import dataclass
from datetime import date
from typing import Mapping, NamedTuple
class Price(NamedTuple):
value: float
@dataclass
class Tariff:
id: str
fluid: str
pricing_type: str
lot_id: str
start_date: date
end_date: date
pricing_properties: Mapping[str, Price]
def __eq__(self, other):
if isinstance(other, Tariff):
return self.id == other.id
return NotImplemented
Repositories
Une fois que l’entité est créée, le repository s’occupe de son insertion dans la base de données, son édition et sa persistance.
Pour résumer cette partie, le modèle du domaine doit appartenir à la couche domaine de l’application, il est découplé des modèles des autres domaines, et il est constitué de plusieurs éléments permettant de représenter des objets métier, de les créer, les gérer et les persister.
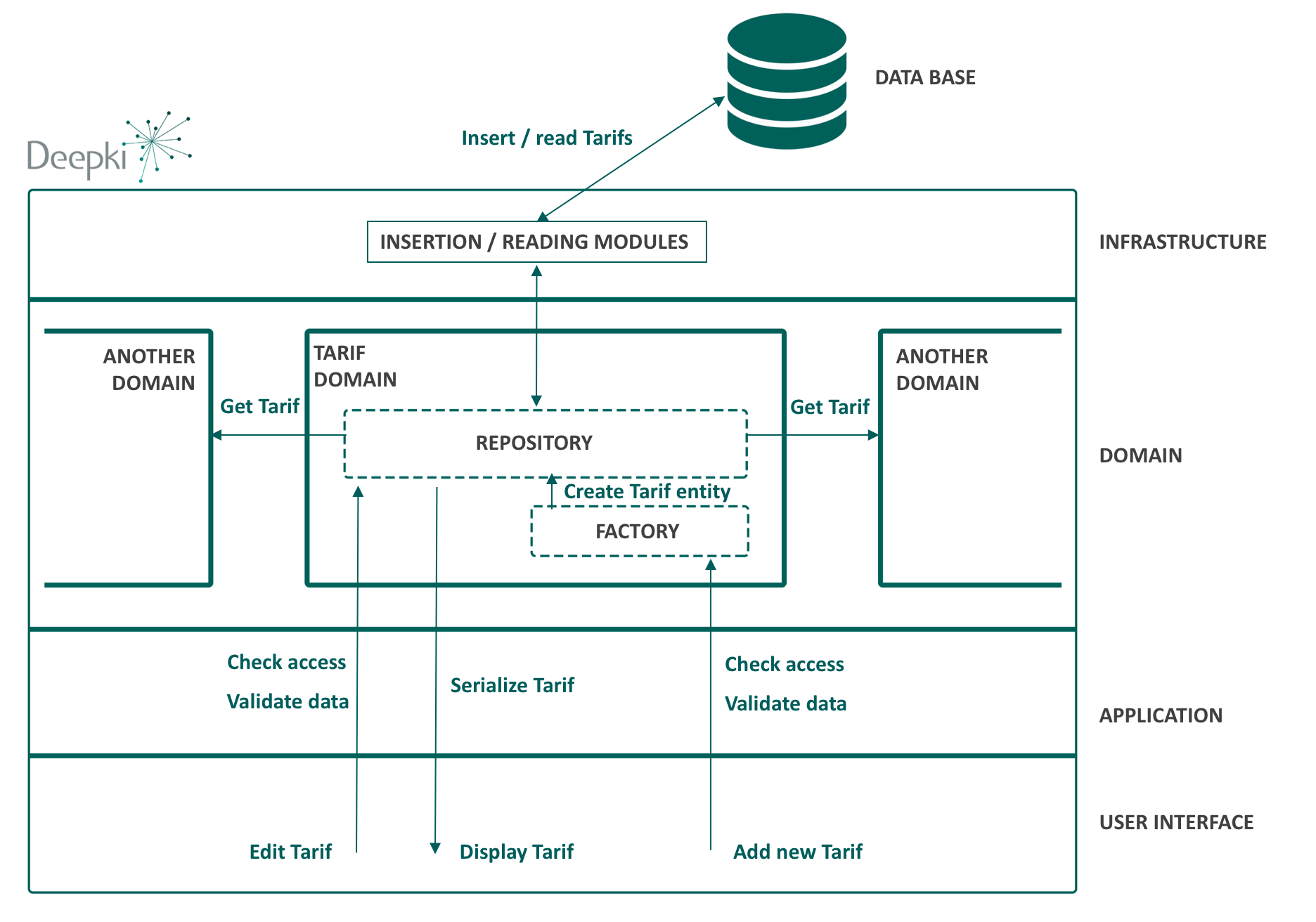
Remarque: Les nomenclatures utilisées dans le code et dans le schéma sont traduites en anglais.
Conclusion
Nous avons pu voir comment une nouvelle fonctionnalité pourra être implémentée moyennant l’approche DDD. L’utilisation de cette démarche au sein de Deepki nous permet en tant que développeurs d’avoir un besoin clair et un langage partagé avant de commencer le développement, de cadrer notre conception et de produire un code propre et robuste. Les fruits de cette démarche sont donc récoltés lors des échanges constructifs avec les chefs de projets autour de ces domaines, ainsi que lorsque les nouvelles exigences qui concernent ces domaines sont facilement et rapidement implémentées.
En plus du DDD, d’autres approches tel que le BDD et le TDD peuvent intervenir à d’autres niveaux de la conception d’une application. Dans un prochain article, nous verrons plus en détail ces approches et comment elles se complètent avec le DDD afin d’avoir une meilleur qualité du code produit.
Cette entrée a été publiée dans programmation avec comme mot(s)-clef(s) python, DDD
Les articles suivant pourraient également vous intéresser :
- La bonne et la mauvaise review par Sébastien Bizet
- Dark mode vs Light mode : accessibilité et éco-conception par Jean-Baptiste Bergy
- Principes SOLID et comment les appliquer en Python par Mariana ROLDAN VELEZ
- Pydantic, la révolution de python ? par Pablo Abril
- Comment utiliser les fixtures pytest en autouse tout en maîtrisant ses effets de bord ? par Amaury Boin
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.