Comment manipuler un DataFrame Pandas avec le MultiIndex ?
Pandas est une librairie python qui permet de manipuler les données en colonnes. Elle est très utilisée dans le monde python, et Deepki ne fait pas exception à la règle : nous sommes utilisateurs de Pandas depuis le début de notre travail.
Pandas peut présenter les données en une dimension (Series) et en plusieurs dimensions (DataFrame). En général, un
DataFrame présente les données en deux dimensions. Il y a l’index qui peut donner un nom à chaque ligne ; il y a aussi
columns qui peut donner un nom à chaque colonne. Par ailleurs, Pandas supporte le MultiIndex qui permet de manipuler
un DataFrame avec un nombre arbitraire de dimensions.
La documentation de MultiIndex se trouve ici : MultiIndex / advanced indexing
Cet article présente l’efficacité du MultiIndex par rapport à l’utilisation d’un index classique et les trois méthodes
stack, unstack et pivot pour ranger le MultiIndex. Bien manipuler le MultiIndex peut nous aider à réaliser les
analyses de données sophistiquées.
1. L’efficacité du MultiIndex
Illustrons ce sujet avec un example.
On voudrait analyser la production agricole dans les provinces de France. Deux entreprises, a et b, mettent à
disposition leurs données, mais a n’a pas toutes les données disponibles.
On va donc utiliser les données de b pour compléter les données manquantes afin de finaliser un tableau concernant la
production agricole pour les deux entreprises.(l’unité utilisée sera 1000 tonnes)
1.1 Comparaison de l’efficacité de sélection entre l’index et le MultiIndex
Créons 2 DataFrames df_a et df_b qui représentent respectivement la production de nos deux entreprises :
df_a = pd.DataFrame({'potato': [50, 25], 'apple': [16, np.nan], 'province': ['Normandy', 'Languedoc']})
df_b = pd.DataFrame({'potato': [60, np.nan], 'apple': [17, 14], 'province': ['Normandy', 'Languedoc']})
# df_single est un dataframe avec un index simple.
df_single = pd.concat([df_a.assign(source='a'), df_b.assign(source='b')], axis=0)
# df_multi est un dataframe avec un index multiple.
df_multi = pd.concat([df_a.set_index('province'), df_b.set_index('province')], axis=1, keys=['a', 'b'])
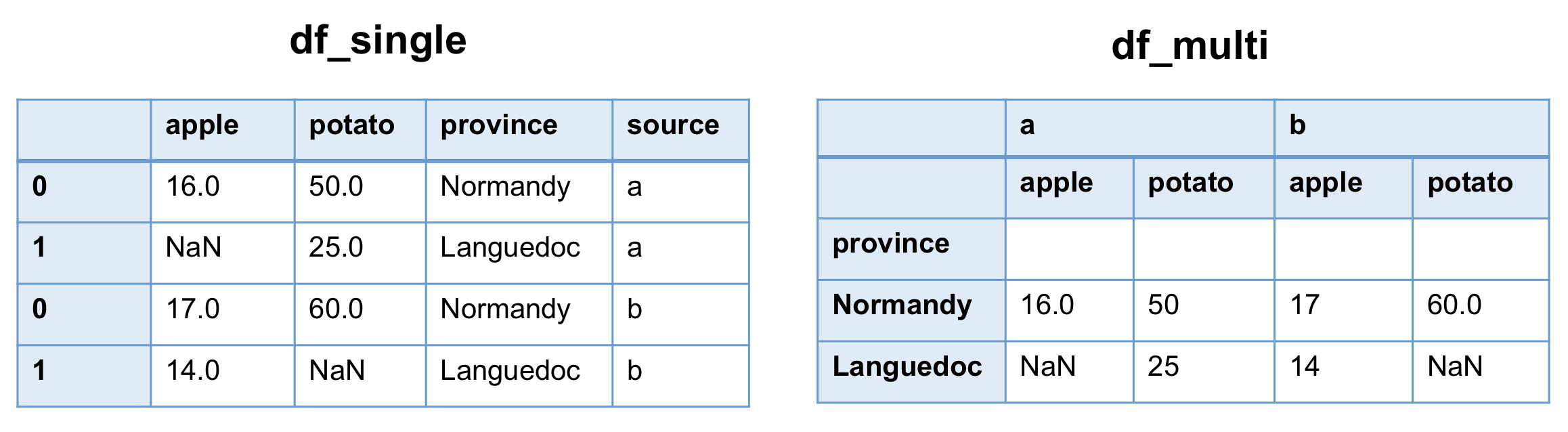
Concernant les deux dataframes df_single et df_multi, la couleur bleu foncé représente l’index sur les colonnes
et sur les lignes. df_multi a le MultiIndex qui contient les deux niveaux :
- Le niveau 0:
['a', 'a', 'b', 'b'] - Le niveau 1:
['apple', 'potato', 'apple', 'potato'].
On voudrait connaître la production totale de apple par l’entreprise a et comparer la vitesse de manipulation en
utilisant nos deux DataFrames :
In [1]: %timeit df_single.loc[df.source=='a', 'apple']
375 µs ± 65.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [2]: %timeit df_multi.loc[:, ('a','apple')]
50.9 µs ± 462 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
- La vitesse de MutiIndex est environ 1000 fois plus rapide que l’index normal pour trouver les données dans le DataFrame
- 0.5ms contre 450ms environ !
1.2 Comparer l’efficacité avec la création d’un nouveau DataFrame
Maintenant nous essayons d’obtenir un tableau avec des données complètes et la source des données comme suit :
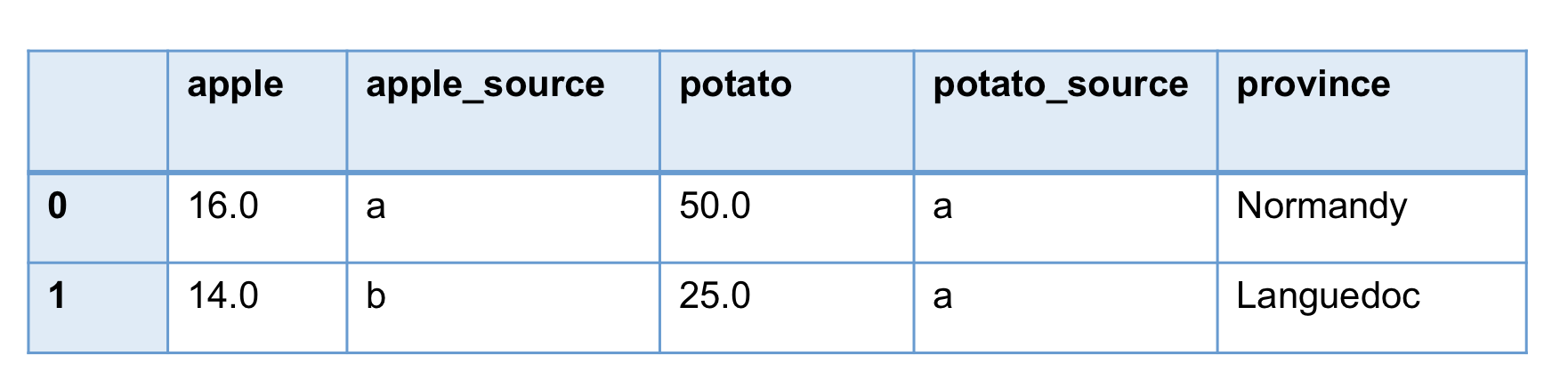
Le df_single a besoin de boucler sur toutes les valeurs de province et de source pour détecter la valeur nulle, et
prendre la valeur des autres sources à remplir, enfin stocker le nom de la source. La complexité en temps est
quadratique (n2). La méthode .loc est très souvent appelée, ce qui prend beaucoup de temps.
Avec le MultiIndex, c’est plus simple et plus rapide :
# Le suffixe est le nom de la source, donc on change
# l'ordre des deux niveaux d'indexes
df_multi = df_multi.swaplevel(0,1, axis=1)
# On utilise les deux méthodes pour prendre les valeurs
# de chaque niveau du MultiIndex
products = df_multi.columns.get_level_values(0).unique().tolist()
sources = df_multi.columns.levels[1].unique().tolist()
for p in products:
# On crée la colonne (p, '') et (p, 'source') pour stocker le résultat
df_multi[p, ''] = np.nan
df_multi[p, 'source'] = np.nan
for s in sources:
try:
# On garde la valeur initialisée
check_init = df_multi[p, ''].isnull()
# On boucle sur toutes les sources pour remplir la colonne (p, '')
df_multi[p, ''] = df_multi[p, ''].fillna(df_multi[p][s])
# On garde la valeur après l'avoir remplie
check_after = df_multi[p, ''].isnull()
# Si check_init et check_after sont différents, on stocke
# le nom de cette source dans la colonne (p, 'source')
df_multi.loc[(check_init) & (~check_after), (p, 'source')] = s
except KeyError:
pass
# On joint les deux niveaux de l'index par `_`
df_multi.columns = df_multi.columns.to_series().str.join('_')
# On renomme le nom de la colonne qui a `_` à le fin
cols_rename = {c: c[:-1] for c in df_multi.columns if c[-1] == '_'}
df_multi = df_multi.rename(columns=cols_rename).reset_index()
1.3 L’utilisation de .loc
On peut appliquer .loc au DataFrame pour localiser (et changer) les valeurs d’une colonne ou une cellule par les
conditions sur le DataFrame avec seulement un index ou plusieurs indexes.
Le MultiIndex peut prendre le même résultat par df_multi['a']['apple'] et df_multi.loc[:, ('a','apple')], mais
quelle différence entre ces deux méthodes ?
On applique une fonction à une colonne :
df_multi['a']['apple'] = df_multi['a']['apple'].apply(lambda x : x + 1)
""" On obtient ici une erreur :
[INFO] (SettingWithCopyWarning)
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
"""
df_multi.loc[:, ('a','apple')] = df_multi.loc[:, ('a','apple')].apply(lambda x : x + 1)
C’est df['a']['apple'] qui génère l’erreur, parce que :
- D’abord, il sélectionne
le niveau 0 est égal à 'a'et retourne un DataFrame, ensuite il sélectionnela colonne 'apple'et retourne une Series. - L’étape 1 réalise les deux opérations individuelles, chaque opération peut rendre une copie d’une partie des données.
- On essaie en fait de modifier la copie des données et non le DataFrame original.
df.loc[:, ('a','apple')] fonctionne parce que:
- Il peut directement passer
(:, ('a','apple'))à__getitem__, Pandas le manipule comme une entité. - Il est plus rapide que
df['a']['apple']
2. Les trois méthodes stack, unstack et pivot
Ces trois méthodes de Pandas nous permettent de manipuler des tableaux.
2.1 stack et unstack
stack et unstack se concentrent sur la manipulation de l’index :
stacktransforme un tableau à deux dimensions (un index de la colonne, un index de la ligne) en un tableau à une dimension (seulement l’index de la ligne).unstacktransforme un tableau à une dimension (seulement l’index de la ligne) en un tableau à deux dimensions (un index de la colonne, un index de la ligne).
La relation entre eux est inverse comme suit :
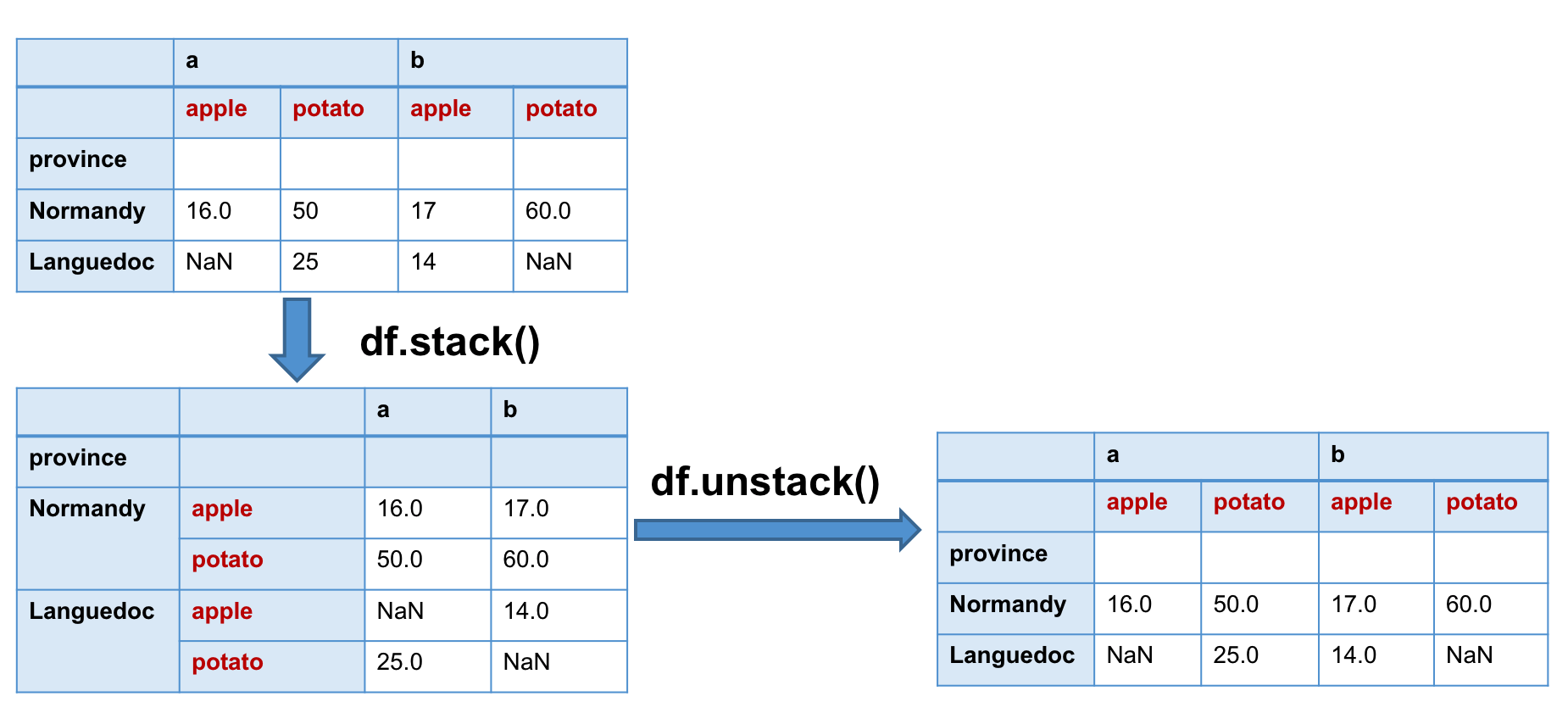
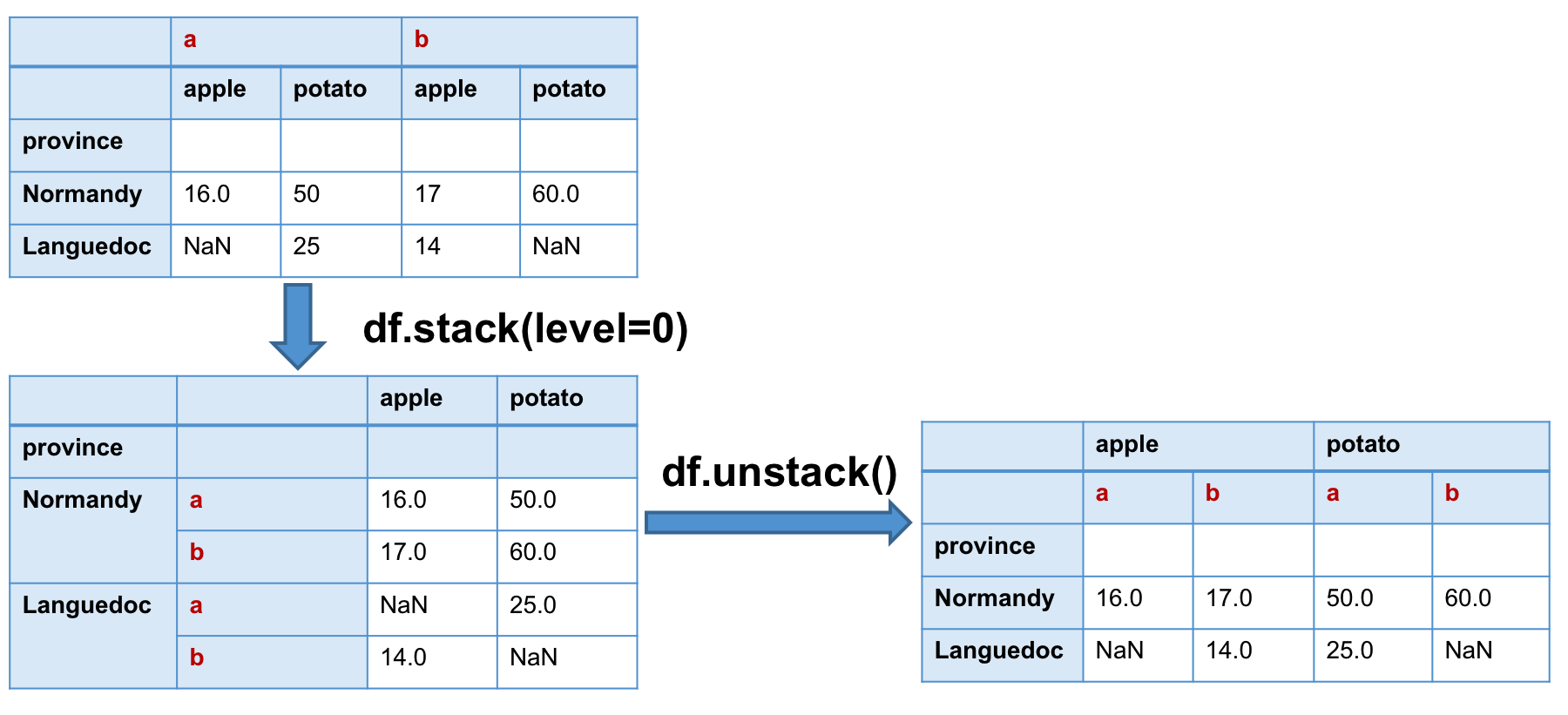
En comparant les paramètres de stack(self, level=-1, dropna=True) et unstack(self, level=-1, fill_value=None), on
observe que ces deux méthodes partagent le paramètre level. La valeur par défaut de ce paramètre (-1) signifie que
la transformation se réalise sur le dernier index (le plus intérieur). Le valeur de level contrôle quel niveau d’index
transformer. Mais il ne peut pas contrôler la position de l’index dans le résultat, il devient toujours le dernier index
du MultiIndex.
2.2 pivot
pivot se concentre sur la manipulation de values. Il peut transformer le DataFrame en deux dimensions à plusieurs
dimensions par les paramètres pivot(self, index=None, columns=None, values=None) :
index(optional) sert à définir la colonne qui sera le nouvel index du tableau. Si non renseigné, l’index déjà existant est utilisécolumnsreprésente la colonne a utiliser pour créer les nouvelles colonnes du tableauvalues(optional) sert à définir les colonnes a utiliser pour remplir le tableau. Si non renseigné, toutes les colonnes restantes seront utilisées
La relation entre unstack et pivot est très intéressante. On peut dire que pivot est l’emballage de unstack, il
ressemble à l’action qui consiste à créer le MultiIndex par set_index, ensuite unstack reconstruit le DataFrame.
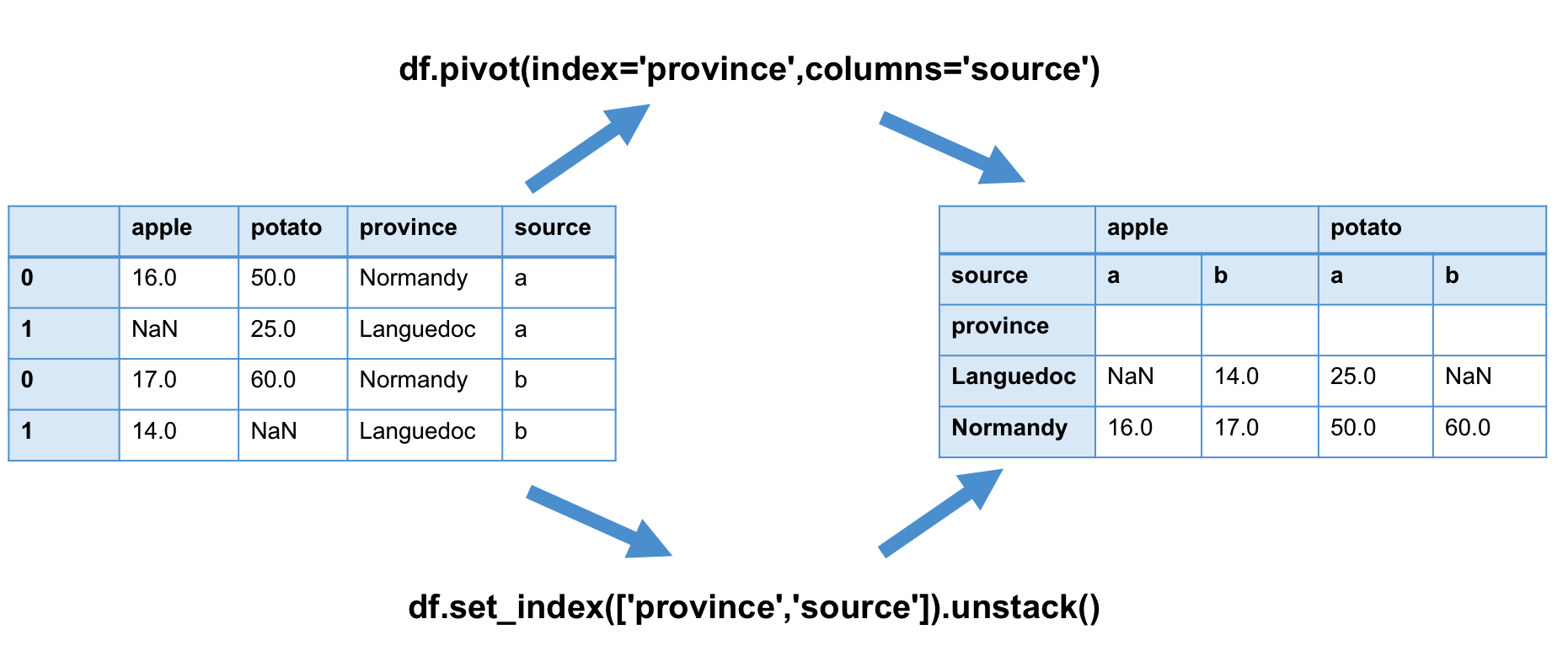
Il y a un point très important pour utiliser pivot :
pivot va lever l’erreur ValueError: Index contains duplicate entries, cannot reshape quand le DataFrame contient des
lignes avec des doublons. Dans ce cas, on doit utiliser pivot_table : cette fonction applique la fonction d’agrégation
numpy.mean aux lignes avec des doublons par défaut.
3. Conclusion
Le MultiIndex est l’extension de l’Index. On a vu comment utiliser le MultiIndex et comment fonctionnent les fonctions
stack/unstack et pivot. Le MultiIndex nous ouvre un grand nombre de possibilités de manipuler et analyser des
données complexes.
Cette entrée a été publiée dans programmation avec comme mot(s)-clef(s) python, pandas
Les articles suivant pourraient également vous intéresser :
- La bonne et la mauvaise review par Sébastien Bizet
- Dark mode vs Light mode : accessibilité et éco-conception par Jean-Baptiste Bergy
- Principes SOLID et comment les appliquer en Python par Mariana ROLDAN VELEZ
- Pydantic, la révolution de python ? par Pablo Abril
- Comment utiliser les fixtures pytest en autouse tout en maîtrisant ses effets de bord ? par Amaury Boin
Vos commentaires
I always struggle to remember how to handle multi indexes in the columns… Will read :)
Postez votre commentaire :
Votre commentaire a bien été envoyé ! Il sera affiché une fois que nous l'aurons validé.
Vous devez activer le javascript ou avoir un navigateur récent pour pouvoir commenter sur ce site.